

こんにちは、sodaの古橋です!
久しぶりの技術ブログ投稿になります。
今回は技術紹介ではなく検証系の記事です。
これまで私のブログでは、自然言語の文章から中心的な話題(=トピック)を抽出する「トピックモデル」について、発展形や派生手法も含めて何度か紹介してきました。
↓過去記事です。興味のある方はぜひ!
- トピックモデルとは?
- SLDAを用いたレビュー解析
- BERTとトピックモデルの融合-BERTopic
が!
最近はそのへん、大規模言語モデル(LLM)に全部おまかせでいいんじゃない?という流れが来ている気がします。
人間が頑張って専用のモデルを組み立てるよりも、LLMに「いい感じにトピック抽出してね」と頼むほうが手っ取り早い、そんな時代でございます。
↓実際にLLMでトピック分析をしてみた記事
- 自動トピックモデリングにチャレンジ!
・・しかし!
LDAなどのトピックモデルと違い、LLMではどんなプロンプトで、どんなデータを食べさせるかによって結果が大きく変わります。
従来の確率モデル(LDAなど)の時代は、手法としてはすでに確立されていて、「どのモデルを使うか」「前処理どうするか」「出力をどう解釈するか」といったアウトプット設計の悩みが主でした。
しかしLLMを使うようになってからは、そもそもどう推定させるのがベストなのか?
つまり、「より人間の肌感覚に近いトピックを、なるべく効率よく、どうやってLLMに推定させるか?」という、推定方法そのものに頭を悩ませるようになりました。
そうです、これが今界隈を静かにざわつかせている──
「LLMでトピック推定どうやる問題」
ということで今回は、このテーマについていろいろと検証してみたいと思います。
ではさっそく、いってみましょう!
手法のご紹介
今回は以下の3パターンで、それぞれLLMを使用したトピック推定を行い、メリットデメリット、精度の違いなどを整理できたらなと思います!
1.トピックツリーを用いた階層的なトピック推定(TopicGPT[1])
2.事前に文章ベクトルのクラスタリングを行い代表単語を用いてトピック推定(GPTopic[2])
3.直接文章を投入して逐次的にトピック推定
上2つはarXivで公開されているトピック推定手法です。
最後は冒頭でも挙げた「いい感じにトピック推定して」の丸投げ戦法です。
▪️使用データ
ライブドアニュースコーパスの「ITライフハック」カテゴリの記事からランダム300本。
なかなかバリエーション豊かで、トピック推定にちょうどよい素材感です。
▪️LLMモデル
[gpt-4.1-nano]
APIコストがgpt4o-miniより安く、それでいて各種ベンチマークスコアは4o-miniを上回るという、非常にコストパフォーマンスが良い、実験にはうってつけのモデルです。
ちなみにコンテキストウィンドウは4oの約13万から100万トークン以上に爆増しています。
急激に増えすぎて嘘なんじゃないかと思うほどです。
トピックツリーを用いた階層的なトピック推定
まずはTopicGPTという論文で紹介されている、LLMをフル活用して階層的にトピック推定を行う手法です。OSSで公開されているので気になる方は是非お試しを(TopicGPT)。
ざっくり以下の流れでトピック推定を行います。
TopicGPTの流れ
- 1. 文章全体のメイントピックを推定
- 2. メイントピックの Refinement(洗練)
- 3. 各メイントピックに紐づくサブトピックを推定
1のメイントピック推定は1文章ずつ実施し、トピック一覧を逐次更新していきます。
(LLMに対して、既存トピックに該当する場合はそのまま出力、新たなトピックが必要な場合はそれを出力というように指示)
2のメイントピックの洗練は冗長なトピックを結合、削除していく処理です。
このあと全文章に対してトピックを割り当てる機能があったり、メイントピック推定時にはトピック一覧のサンプルを投入することができたりと、OSSとしてもかなり使いやすくまとまっています。
但しOSSは英語ベースなので、日本語文章の推定を行うにあたって事前にプロンプトを日本語化してから実行してみました。
では、さっそく結果を見てみます。
以下はメイントピック推定の結果です。
TopicGPTでの推定結果(メイントピック)
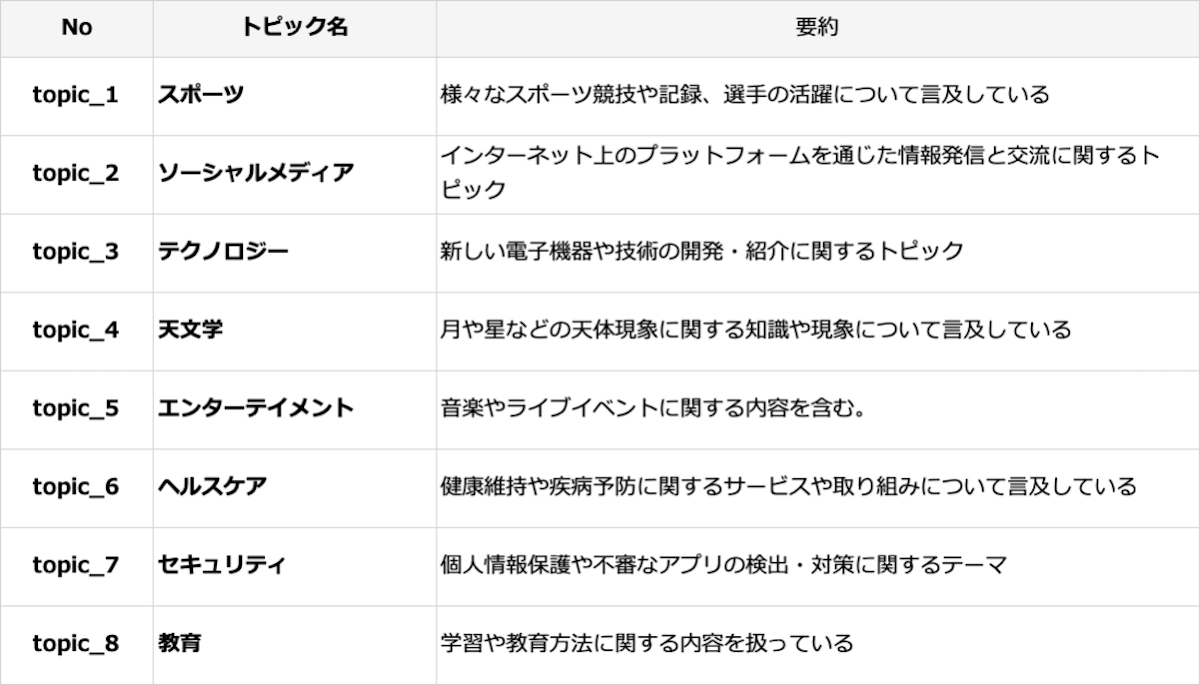
うーん...微妙
非常に微妙です。
スポーツとか一応記事内にでてきたりはするのですが、ウェアラブル系、フィットネス系の端末のレビュー記事が殆どで、要約に書いてあるようなスポーツ競技の記録についてはフィーチャーされていません。
そう考えると「スポーツ」でトピックとして抽出するのはあまり適切ではないはず・・・。
そして、肝心のIT関連のトピックが「テクノロジー」という括りでざっくりまとめられてしまっている感がありますね。
メイントピック推定用のプロンプトに「階層の上位トピックとして機能し得る汎用的なトピックを推定・・」という指示文が含まれているため、その影響が出ているのかもしれません。
そこで、前述したサブトピック抽出を「テクノロジー」トピックで試してみたところ、「ハードウェア、ソフトウェア、ネットワーク、ストレージ・記録、周辺機器・アクセサリー・・・」という感じで、合計14の関連サブトピック抽出できていました。
ちょっと区分けが細かすぎる気がしないでもないですが、雑多な文章が多く全体を階層的に整理したいという時などには使い勝手が良さそうですね!
ただ、メイントピックの「スポーツ」とか「天文学」はあまり今回の文章群には相応しくない結果かなと思うので、総評としては微妙とさせていただきました。。。
クラスタリングと代表単語を用いたトピック推定(GPTopic)
次はGPTopicという論文で紹介されている手法です。
同じくOSSで公開されているのですが、リポジトリ名が先ほどのものと同じ「TopicGPT」となっていて混同しやすいので注意しましょう。
TopicGPT(GPTopic)
※ 便宜上こちらの手法をGPTopicと呼びます。
こちらは事前に文章や単語のEmbeddingを取得してクラスタリングした後に、その情報を用いてLLMによるトピック推定を行います。
OSSは例の如く英語前提で構築されているので、日本語で実施する場合はプロンプトや前処理、分かち書きのロジックなどを変える必要があります。
ちなみにこれ実際にやってみたところ、思った以上に変更が必要な箇所が多かったので、自分でそれっぽいものを1から作った方が早いかもしれないです・・・。
以下、GPTopicの流れです。
GPTopicの流れ
- 1. 全文章のEmbedding(文章ベクトル)を抽出
- 2. UMAPで文章ベクトルの次元圧縮
- 3. HDBSCANでクラスタリング
- 4. 凝縮型の階層クラスタリングを用いて3で抽出したクラスタを任意の数に削減
- 5. 各クラスタの※代表単語を用いてトピック名称と要約をLLMにより推定
以下の2種類の代表単語をLLMに渡すことで、統合的にトピック名称を推定しています。
- ・意味的代表単語 - クラスタの重心(文章ベクトルの平均)とのコサイン類似度が高い単語
- ・統計的代表単語 - 各クラスタでtf-idf値が高い単語
日本語でやるにあたり、形態素解析はJanomeで実施しました。
手順3あたりまでは以前このブログでも紹介したBERTopicと同じような流れですね。
コンテキストウィンドウが限られていて多くの文章を一度にLLMに入れられない時は、私もこれと似たような方法でトピックを推定をしていました。
事前にトピックの代表となる文章(単語)に絞った上でラベル付けを行うため、限られた情報でも精度良くトピック名称を推定できそうです。
事前処理がけっこう入るので、時間はかかりますがトークン数を節約できるのがメリットです。
デメリットは、そもそもクラスタリングが上手くいっていないとLLMでのトピック推定もうまくできないという所ですね。。。
特にUMAPやHDBSCANはハイパーパラメータも多いので、そこの調整次第で大きく結果が変わりそうな気もします。
では、こちらの方も結果を見てみましょう(パラメータはデフォルト値を使用)。
GPTopicでの推定結果

こちらも微妙。。。
「日常生活と感情」が2つできてしまってますし、そもそも表現が曖昧すぎて内容がよくわからないです・・. クラスタリングがうまくいっておらず、トピック毎の単語の重複が多くなってしまったせいでこのような結果になったと思われます。
そもそもこのGPToicという手法はトピック命名時に元の文章を一切見ておらず、あくまでクラスタ内の重要単語のみを見てトピック名と要約を生成しているので、日本語のように語彙が多く形態素解析も難しい言語だと難易度が跳ね上がるのかもしれません。
各トピックの所属文章も推定時の入力にするなどカスタマイズを入れつつ、トークン数を極力減らしたいというシーンでは役に立つ手法かなという感じです。
直接文章を投入して逐次的にトピック推定
最後は小細工一切なしで、文章をある程度のまとまりでLLMに直接投入するという単純明快な方法で推定してみます。
まさに力こそパワー。完全にLLMの処理能力任せです。
とはいえ、コンテキストウィンドウギリギリまで詰め込むと精度が下がりそうな気がするので、一応事前に文章をチャンク分割→10000トークンほどを目安に再結合し、複数回逐次的にトピック推定するという形式でやってみようと思います。
文章まるごと投入なのでGPTopicよりもトークン数は嵩みますが、情報の削ぎ落としが少なくなるのでLLMの能力さえ高ければこの方法で十分通用しそう・・なんなら一番精度が良い可能性も全然ありそうです。
では、結果です。
文章丸ごと投入でのトピック推定結果

はい
かなりいい感じに見えますね・・
GPTopicで抽出されたトピックを殆どカバーした上で、より広範にトピックを抽出できています。
意味的な区分けも他の手法よりもしっかりしている印象です。
「こっちだと映像技術に関連するトピックがない」など、細かい部分を突き詰めれば弱点はあるかもしれませんが、結局最終的には人の目でトピックの確認・調整を行うことは不可欠にはなると思うので、初期のトピック抽出としては十分な精度と言えるでしょう。
コンテキストウィンドウが2000とか4000文字程度だったころはこんな力技は考えもしなかったのですが、技術の進歩は恐ろしいですね。
なんならトークンで区切って逐次投入みたいな小細工をしなくてもいい感じの結果が得られるかもしれません(笑
なにより時間もかからずカスタマイズの余地も多いのが良いです。
各手法それぞれメリットデメリットはありますが、「基本は力技で全然オッケー」という感じの結果となりました。
まとめ
というわけで、今回はLLMを使った3種類のトピック推定手法を比較してみました。
やり方次第で思った以上に差が出たのが面白いところです。
TopicGPT: 手順が整理されていてOSSも優秀。階層的な構造が作れるのは魅力ですが、日本語対応にはひと手間必要。
GPTopic: 前処理に手がかかるぶん、トークン数はかなり節約可能。ただし、クラスタリングがうまくいかないと全体が台無しに...。こちらも日本語対応に課題
直接投入法: とにかく文章をそのままLLMに渡して推定させる。シンプルかつ今回の検証では最も精度が高い結果に。
やはりモデルの性能が向上してくると「極力情報を削ぎ落とさずに、そのままLLMに突っ込む」というアプローチが、ますます強力になってきますね。
とはいえ、今回は「トピック推定」という比較的シンプルなタスクだったからこそ、うまくいった面もあります。 現実には、丸投げでは精度が出ないタスクもまだまだ山ほどあるはずです。
だからこそ今後も、
「このタスクはそもそもどんな構造か?」
「どこまでLLMに任せて、どこを人や別の仕組みで補うか?」
といった視点でタスクをきちんと把握・分解し、LLMを組み込む最適なフローを設計する力が、ますます重要になってくると思います。
今後は今回の検証を活かして、より実用的なトピック分類フローを模索していければと思います!
ここまで読んでいただきありがとうございました。
ではでは!
[1] Chau Minh Pham et al. (2023). TopicGPT: A Prompt-based Topic Modeling Framework.
[2] Arik Reuter et al. (2024). GPTopic: Dynamic and Interactive Topic Representations.





