

こんにちは!
sodaの古橋です。
巷ではChatGPTが言語モデル界隈を席捲しており、多くの人が最新対話型AIの進化を実感されていますね。
私も業務でちょっとわからないことや、これってどうやるんだっけ?と思うことがあると、ググるのではなくChatGPT先生に聞いてみるか―となる場面が増えてきました。
サードパーティ製品も急速に増えると同時に規制の話も盛んに出ており、色んな意味で今一番ホットな分野ですので、今後の動向も要注目ですね。
さて、今回はChatGPTのように対話こそ出来ないものの、ビジネスの場ではちょっと使えるかも?というモデル、BERTopicなるものを紹介したいと思います。
BERTとTopicModel両方に馴染みのある方だと、その二つが融合されて何かとんでもない言語モデルが出来上がったのではと期待しそうな名前ですが、始めに概略を書いておくと「BERTで良さげな文章ベクトルを抽出して、それをいい感じにトピックモデル形式のアウトプットに仕上げていくよ」という、特定のモデルを指すのではなくBERTの文章ベクトルの活用法の一種となっています。
若干肩透かし感もありますが、実際にトピックモデルを使っていると「アウトプットは分かり易いんだけど、単語の共起性だけでモデル化してるからそもそもモデルとしての表現力に乏しいな・・・」と感じることも多々ありまして、BERTを用いることで文章の意味を細かく汲み取れるようになった表現力の高いトピックモデルと考えると個人的にはなかなか惹かれるものがあります。
今回もまず、1回目の当記事でBERTopicがどんなものなのか概略を紹介し、次回記事で実データを使った検証という形で進めてみようと思います!
BERTopicの全体の流れはざっくりこんな感じになります。
① テキストデータをBERT(Sentence-BERT)に入力して文章ベクトルを抽出
② UMAPで文章ベクトルの次元数を圧縮
③ HDBSCANで圧縮された文章ベクトルをクラスタリング
④ c-TF-IDFでクラスタ(=トピック)毎の重要単語を抽出
では、順を追って詳細を見て見ましょう。
というわけでまずはBERTによる文章ベクトルの抽出です。
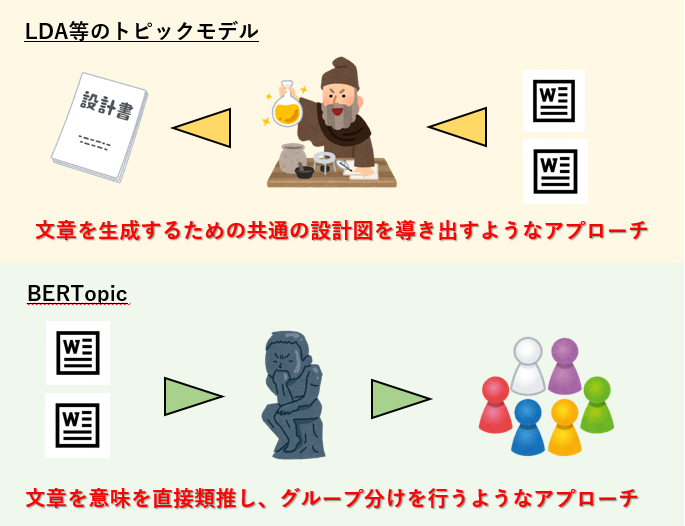
トピックモデルの場合、観測された文書群からそれを生成するための共通の設計図を導き出すようなイメージのアプローチでしたが、BERTでは文書群の内容・意味を直接類推します。
類推した結果を数値データとして形にしたのが文書ベクトルで、BERTopicではこの文章ベクトルを加工していくことで、最終的にトピックという形で文章のグループ分けを行います。
通常のBERTで得られる文書ベクトルは、文章毎の単語ベクトルを平均化したり、文末のトークンをそのまま文章ベクトルとして扱ったりすることで得られますが、大概精度が良くないです。
そのため出典元[1]では良質な文章ベクトルを得るためファインチューニングされたモデルであるSentence-Bertを用いて文章ベクトルを抽出しています。
この文章ベクトルはかなり高次元(通常768次元)になっており、「どの単語が何回出現したか」だけを見るトピックモデルと違い、文章の意味、単語間の関係性、細かなニュアンスの違いまで捉えた非常に濃度の濃いと言いますか、情報が沢山詰まった表現力の高い物になっています。
通常のトピックモデルとの文章の扱いの違いで例を挙げますと例えば
「子供に長男が生まれた」 「長男に子供が生まれた」
のような語順を入れ替えただけの2つの文があった時、トピックモデルの場合は単語の共起性のみを見るので、一般的な単語の区切りに沿うとこの2文はどちらも「子供、長男、生まれた、に、が」の5単語で構成されており、単語が同じ=同じ文章として扱われますが、BERTの場合は語順による文脈の違いを汲み取り違う文章として扱ってくれます。
実際、この2文から汲み取れる情報の量には差異があるので、同じ文として扱ってしまうよりも、似てるけど違う文章という方が文章の扱いとしてより正しい気がしますよね。
この表現力の高い文章ベクトルを用いることで、通常のトピックモデルよりも高精度なアウトプットの期待が持てるというわけですね。
また、ステップ①においてはBERTの事前学習モデルを使用する場合にどんなTokenizer(形態素解析器)が使われているかも注意しておきたい所です。
っというのも、BERTの日本語事前学習済みモデルでは、Sentencepieceのような文法的な正しさを無視したTokenizerが使われていることが多いです。
下流のタスクが翻訳であれ感情分析であれ、そのタスクの精度が高ければ別にインプットする文章が内部でどのように単語分割されても特に問題はないので、精度面と計算効率の面から文法的正しさは捨てられているという感じですね。
ところがBERTopicの場合は、文章ベクトルを得ること自体が目的ではなく、トピックという形式を用いてインプットする文書群についての文章、単語単位での情報抽出に主眼を置いているため、人間に解釈出来るような単語分割になっているかという部分も重要になってくるかと思います。
精度を重視したいのか、最終的にトピックの単語単位まで見た時の解釈性を重視したいのか、目的によって適切なモデルを選択(もしくは構築)する必要がありそうですが、逆に言えばこのあたりを柔軟に選択出来るのもBERTopicの強みと言えそうです。
次のステップは文章ベクトルの次元圧縮です。
ステップ①で表現力の高い文章ベクトルが得られたので、その情報量を極力保ったままギュッと高密度に圧縮していきます。
圧縮せずに768次元のデータのままクラスタリングしちゃえば良いじゃんと思わなくもないですが、事前に次元圧縮を行うことで後のクラスタリングの精度向上が見込めます。
特に高次元データにおいては、通常の距離尺度(マンハッタン、ユークリッド等)で計った距離は、実際の距離を正確に表していないことも多いため、そのままクラスタリングを行うと真に近い点同士をクラスタリング出来ず精度が低下する・・ということが起こり得ます。
UMAPは、そんな高次元空間上の異なる点同士の「近さ」を定義し、低次元空間上でも極力高次元空間上での近さと極力同じになるよう配置してくれる次元圧縮手法です。
論文でも言及されていますが、高次元データをHDBSCANでクラスタリングする際は、事前にUMAPで次元圧縮を行うことでクラスタリングの精度が向上しやすいというのは界隈では良く知られているようです。
また、次元を圧縮する際に2次元、3次元まで圧縮を行えば人間の目にも見える形で文書ベクトルを可視化出来ます。
試しに前回ブログで使用したサッカーW杯のツイートデータから幾つか抜粋し、文書ベクトルを2次元まで圧縮して可視化してみましょう。
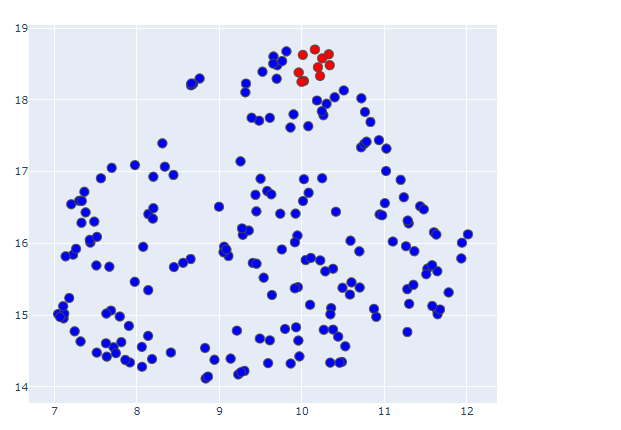
このままだとただ点が散在しているようにしか見えないので、上の方に密集している事前に赤色にしておいた点をピックアップして、元となったツイートを順番に確認してみます。
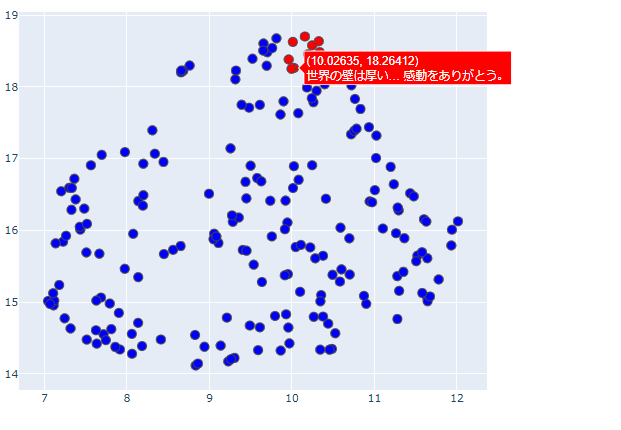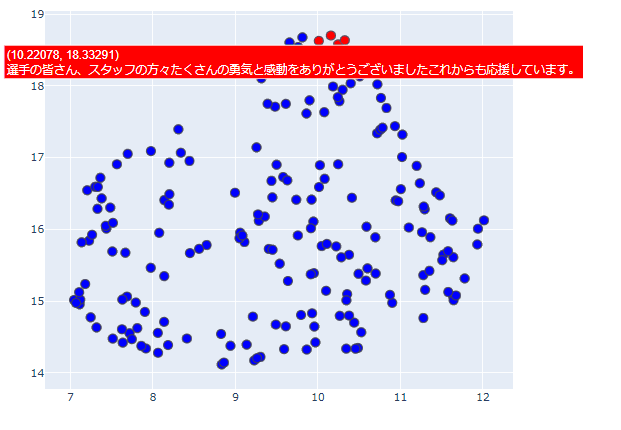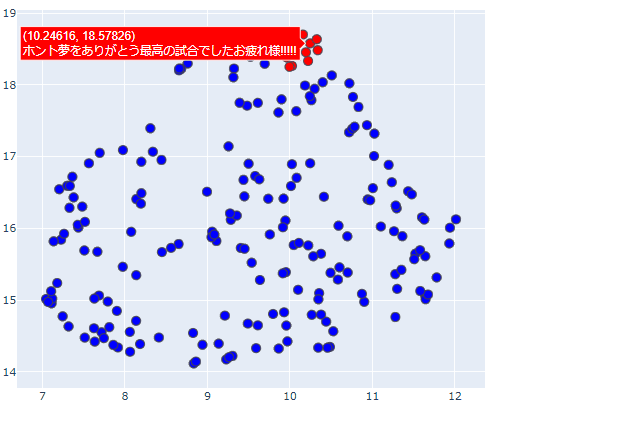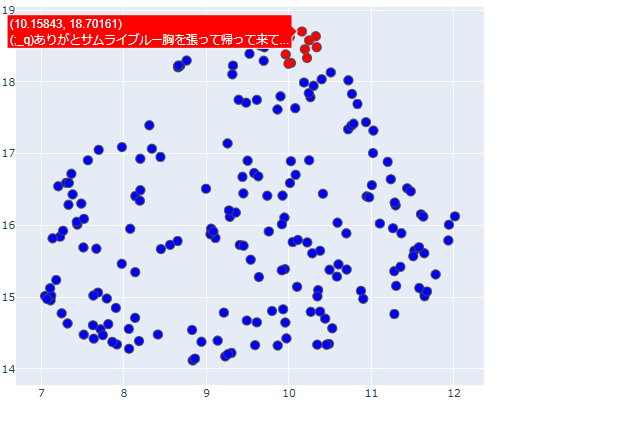
全て試合後の日本代表に対する感謝、労いのツイートになっていますね。
内容的に似たような文章が二次元座標上で密集して配置されているのがわかります。
ちなみに反対の方の座標位置には試合経過に関する文章が多く配置されていました。
このように、精度の高い文章ベクトルを二次元上に可視化するだけでも、どのような意見がどれくらいあるのかざっくり把握することが出来て非常に便利ですね。
UMAPによる次元圧縮を終えたらいよいよHDBSCANによるクラスタリングです。
各文章がどのクラスタ、つまりトピックに属するかを判定します。
HDBSCANは密度ベースのクラスタリング手法で、単純な2点間距離ではなく、データの密集度に基づいた「相互到達距離」という概念を用いて距離計算を行っています。
距離ベースのk-means等の手法と比較しどんな違いが出るのか、簡単な例で見て見ましょう。
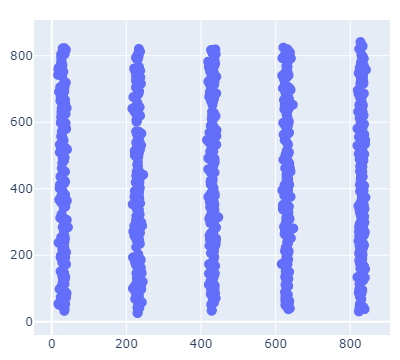
上のデータをクラスタリングしてみたいと思いますが、どう分かれてくれるのが良いでしょう??
恐らく100人いたら99人ぐらいは、縦に伸びた点同士が同じグループになるよう、X軸の値毎に5つのクラスに分かれてくれるのが良さそうと答えるのではないでしょうか。
では、実際にk-means、HDBSCANでクラスタリングした結果を見て見ます。
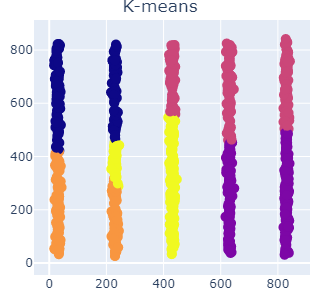
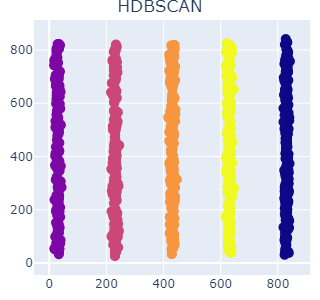
距離ベースのK-meansでは1つの棒に複数のクラスターが混ざってしまっているのに対し、HDBSCANではこちらの意図通り、縦棒1本が1クラスになるようクラス分けしてくれています。
各クラスタの重心からのユークリッド距離に応じてクラス分けされるk-meansに対し、HDBSCANのような密度ベースの手法ではデータ間の距離計算ではなく、一定の半径内にあるデータの数を基準としてクラスタを形成するため、上記のような縦に並んだデータは一つのまとまりとして上手くクラスタリングしてくれるという寸法になります。
HDBSCANは更に、密度ベースのクラスタリング手法の中でも発展的な階層型のクラスタリング手法になっており、高次元で異なる密度のデータ群であっても精度高くクラスタリングを行えるよう構成されています。
必然的に、抽出されるトピックも質の高いものが期待出来るということになりますね。
最後にc-TF-IDFで各クラスタ(トピック)の単語分布の算出、重要語の抽出を行います。
TF-IDFは文章の重要語を抽出する手法として馴染み深いと思いますが、頭にcが付いています。
cはclassのc、つまり、TF-IDFを特定のカテゴリ(今回で言うとクラスター)単位に適応出来るようにした計算になります。
適用出来るようにしたと言ってもそこまで小難しことはやっておらず、HDBSCANでのクラスタリング後、同一クラスターに属する文章群を一つの文章として結合し、クラスター毎に計算を行うという手順で構成されています。
tfの計算は通常のTF-IDFのdocumentの部分をclassに変更しただけです。クラスター単位で単語頻度を求めます。
少し違ってくるのはIDF(逆文書頻度)の部分で、通常のTF-IDFだとここは全文書数 / (単語tが登場する文章数+1)で求めますが、c-TF-IDFの場合は1+(各クラスタの単語数平均値 / 全クラスタの中での単語tの出現回数)で求めています。
前述の通りc-TF-IDFの計算においては同一クラスタの文章を全て繋げて一つの文章として扱っており、通常のIDF計算が上手く機能しない(文章の数が少なく、一つ一つの文章が非常に長くなるため同じ値が多くなる)ため、このような計算にしているのかなと思っています。
意味合い的には通常のIDFと似ていますが、通常のIDFでは特定単語が出現する文章数が増えるとIDF値が下がり、逆に計算対象の文章で何度その単語が出現してもIDF値は下がらないのに対し、c-TF-IDFのIDF値はとにかく対象の単語がどこかのクラスターに出現する度にIDF値が少しずつ下がります。
混乱しないようこのあたりの計算の違いは意識しておきたい所ですね。
また、IDFの計算にBM25を使ったり、単語頻度算出時に平方根を取って高頻度語の抑制をしたり等、計算補正の仕方は沢山あるので、このあたりはデータに合わせて良いアウトプットが出るよう調整してあげれば良いと思います。
結果、下図のようにトピック毎に数値化された重要語を得ることが出来ます。
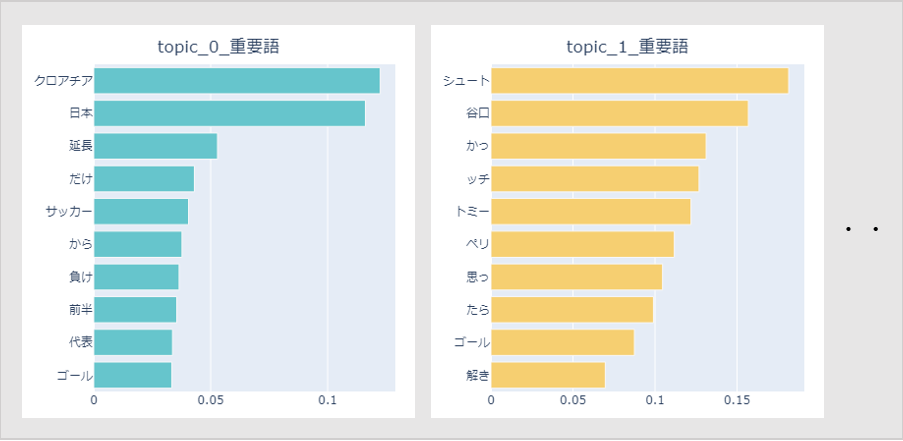
特段ファインチューニング等は行っていないので単語分割は事前学習モデルのTokenizerに完全に依存しています。
固有名詞はあまり抜き出せなさそうなのと、「だけ」「から」等情報としてあまり有用でないものも混ざってくるので、このあたりは次回検証する際には抽出の仕方を考えたいですね。
以上が、BERTopicの概略になります。
ド直球なネーミングになっていますが、中身も高精度の文章ベクトル!高精度の次元圧縮!高精度のクラスタリング!と、とにかく精度の高い手法でトピックモデル風のアウトプットを錬成するというゴリゴリにマッチョな手法でした。
しかしその分効果も絶大で、特に、文脈を加味したベクトル表現という部分は通常のトピックモデルでは出来ない所になってくるので、LDA等ではイマイチ結果に納得感が出ない場合でもBERTopicなら良さそうな結果が抽出出来たという場面は今後沢山出てきそうです。
また、記載した通りBERTopicは特定のモデルを指すというよりも、文章ベクトルを加工する一連の流れという側面が強いので、文書ベクトル抽出、次元圧縮、クラスタリング、重要単語抽出の流れのどこかで今後より高精度な手法が出てきた場合は、適宜その手法を取り入れることが出来るというのが非常に大きなメリットになります。
その意味で行くと、文書ベクトル抽出も別にBERTモデル限定というわけではなく、Doc2VecやSCDV等の別の手法で抽出したものを使っても良いことになります(その場合もはやBERTopicとは呼べなくなりますが。。。)。
次回記事ではこのBETopicを使用して、既存のトピックモデリングとの結果の違いを体験してみようと思います!
ではでは!
参考
[1] Maarten Grootendorst 2022. "BERTopic: Neural topic modeling with a class-based TF-IDF procedure"





