

こんにちは!
sodaの古橋です。
前回記事ではBERTopicの概要を説明しましたので、今回は検証編ということで、実データを使って解析を実行してみようと思います。
使用するデータですが、丁度良い時事ネタもあまり思い浮かばなかったので、今回は楽曲の歌詞データにしてみました。
歌ネット様の歴代歌詞検索ランキングから上位1000曲ほどを対象にしています。
但し1曲=1文書とするとちょっと文が長く、サビでの繰り返し表現等も多いので、各楽曲の出だし1メロディ分のみに絞ります。
いつもであれば解析対象データを先にお見せしていますが、歌詞をそのまま載せるのは著作権的な部分が危ないので今回はやめておきます。。。
さて、今回この歌詞データを使い、BERTopicでやってみたいことは2つです。
・人気楽曲の歌詞の背後にあるトピックと、トピック毎のキーフレーズ抽出
・時系列(発売年)でのトピック、キーフレーズ内容の遷移の可視化
前者は通常のトピックモデル(LDA等)と同様の流れ、後者は時系列トピックモデリング(DynamicTopicModeling)と呼ばれる、トピックの生成過程に時系列による影響を盛り込んだモデルをBERTopicで表現したものになります。
では早速、解析行ってみましょう。
前回ご説明した通り、まずはBERTによる文章ベクトル抽出からスタートです。
モデルはHugging Faceからsonoisa/sentence-bert-base-ja-mean-tokens-v2を使わせて頂こうと思います。
非公開データセットでファインチューニングされた日本語用のsentence-bertモデルです。
こちらのモデルに準備した大量の歌詞データ(文章)を入力し、文章ベクトルを抽出します。
実際に抽出されたものを一部見て見ましょう(ランダムに選んだ25曲分だけ表示します)。
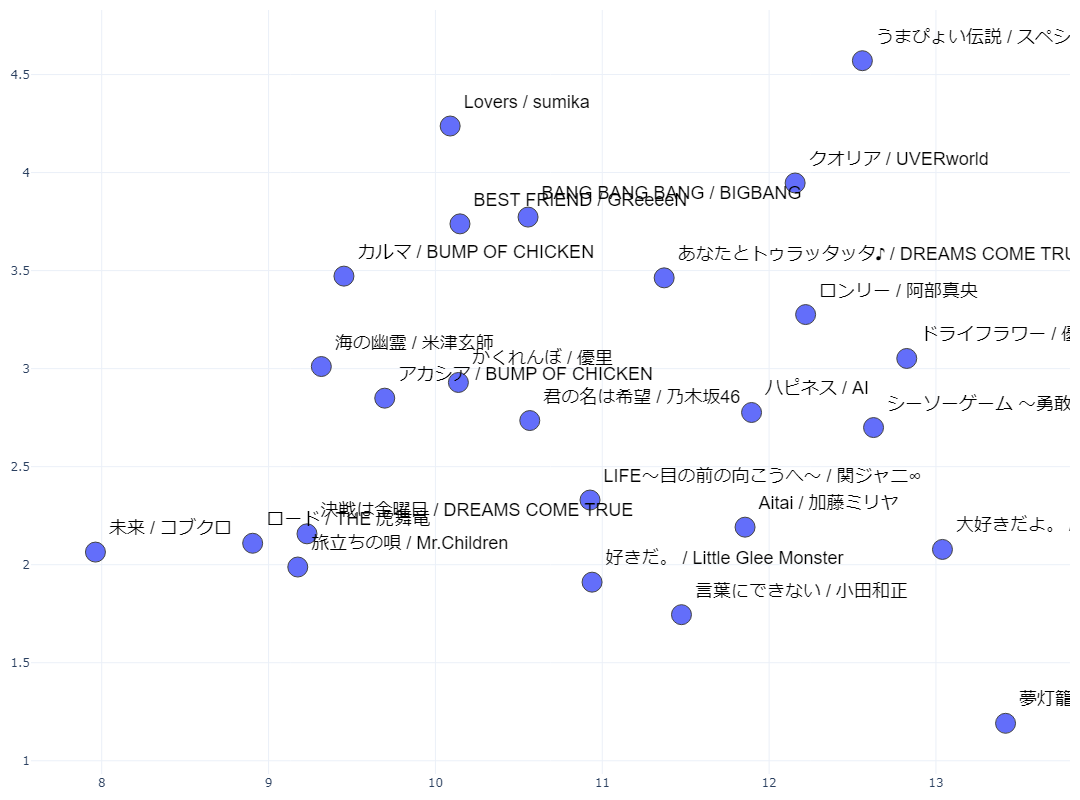 ※アーティスト名+曲名表示にしていますが、入力データは歌詞でやっています
※アーティスト名+曲名表示にしていますが、入力データは歌詞でやっています
一部表記が被って見にくいですが、ご容赦願います。
768次元のベクトルを2次元に圧縮して座標上にプロットしているので、データ間の距離感は元のベクトルと多少なり異なってきますが、意味的に似通った歌詞の楽曲同士がある程度近くに配置されている・・・はずです。
次のステップに行く前に、せっかくなのでこのベクトルを使って類似楽曲抽出をやってみましょう。
全データの中から文章ベクトル同士のコサイン類似度が高い楽曲ペアトップ3です。
1位...類似度83.9%:ただ、ありがとう/MONKEY MAJIK - キミに贈る歌/菅原紗由理
2位...類似度82.7%:ビリーヴ/GReeeeN - 涙/ケツメイシ
3位...類似度82.4%:家族になろうよ/福山雅治 - 100年先まで愛します。/ソナーポケット
・・・どうでしょうか?
少なくとも出だしの部分は、ある程度意味的に似たような歌詞になっているはずですが・・。
本当に似ているか気になる方は、是非実際に歌詞を調べてみて下さいね!
類似楽曲抽出自体はBERTopicとは何も関係がない、ただ興味本位でやってみただけのものですが、このような文脈を読み取った埋め込みベクトルによる類似度抽出も、通常のトピックモデルでは出来ないBERTならではの強みですね。
やや本筋か逸れてしまいましたので、続いての次元圧縮ステップに行ってみましょう。
次は768次元の文章ベクトルをUMAPで次元圧縮、HDBSCANでクラスタリングを行います。
次元圧縮の目的は、前回記載した通りクラスタリングの精度向上ですね。
ここで疑問として湧き上がってくるのが、何次元に圧縮するのが一番精度が上がるの?
という所なのですが、これに関しては「明確な答えは無い」ということになると思います。
いわゆる「データ次第」というやつですね。
次元数が少なすぎるとクラスタリングを行うための情報が不足してしまいますし、多すぎてもデータ点同士の距離の把握が難しくなり、結果クラスタリングの精度は悪化してしまいます。
このあたりのパラメータの設定ですとか、そもそも次元圧縮・クラスタリングにどの手法を用いるか等によっても後の結果が大きく変わってくるので、実業務等でしっかりしたアウトプットを出したい時は地道なトライアンドエラーが必要になってくるかと思います。
まずは圧縮後次元数15ぐらいで試してみましょう。
クラスタリングを行うと、こんな感じに文章ベクトルがクラス分けされます。
(15次元でクラスタリングした結果を2次元圧縮後の座標に当てはめて表示しています)。
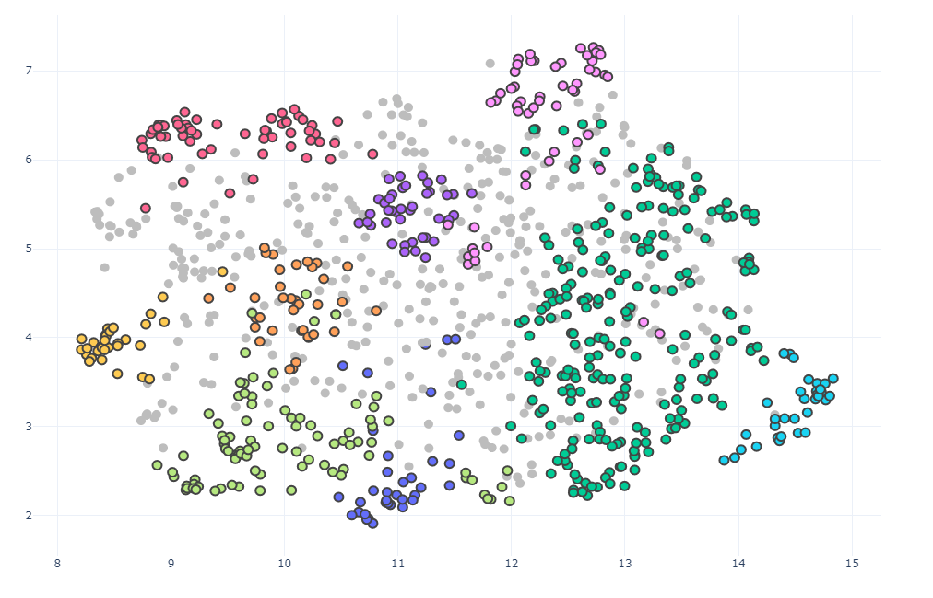
色がグレーになっているのは「どのクラスタにも属さない」と判定された文章になります。
独創性の高い歌詞の楽曲はここに分類されそうです。
また、図を見ると「近い点同士で同じクラスになってない所があるじゃん」と思うかもしれませんが、実際のクラスタリングは15次元空間上で行っており、2次元で見える距離とはまた違った距離に基づいてクラス分類が行われるため、点同士の距離はあまり厳密に気にしなくても大丈夫です。
無事に楽曲のクラスタリングが出来た所で、次の単語分布計算のステップでより詳細に、各クラスタがどんな内容になっているのか確認して行きましょう。
最終ステップ、単語分布(C-TF-IDF)の算出です。
この分布を確認することで各トピックにどんな単語が所属しているのか、それにより文書群がどんなトピックに分けられたのか類推することが出来ます。
単語分布を出すには当然文章を単語に分割した情報が必要になってきます。
文章ベクトルを抽出する時(Sentence-BERTに文章を流す時)にTokenize(=単語分割)されたデータを使用しているので、この単語データを用いてC-TF-IDF計算を行うのが自然な流れなのですが、BERTモデルでの単語分割結果をそのまま使うと、固有名詞が殆ど抽出出来ていない上に品詞の選別等も行っていないので、単語情報として見た時にトピックの内容理解が難しくなりがちです。
例えば「憧れるのをやめましょう・・・」から始まるWBC決勝での大谷選手の名言をデフォルトのTokenizerにあてはめると、こんな感じになります。

固有名詞は一つも抽出出来ていないですし、トピックの理解に役に立たなそうな助詞や助動詞も全て付いてきてしまうので、出来ればこの段階で省いておきたいところです。
後の解析をしやすくするため、今回は文章ベクトル抽出時のTokenizerとは別で用意した情報抽出用のTokenizerで単語分割を改めて行い、それを元にC-TF-IDF計算を行うという流れで解析を行ってみました。

単語は原形に、品詞も名詞、形容詞、動詞のみに絞って大分スッキリしました。
では、実際にこのTokenizerを使って歌詞データから抽出した単語分布を一部見て見ましょう。
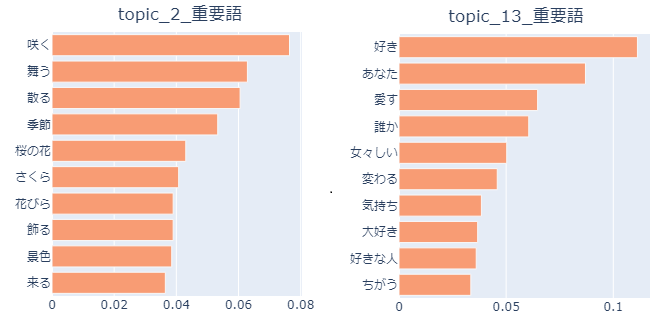
左が桜を題材にした楽曲、出会いと別れ等のテーマが盛り込まれた歌詞の曲が多そうです。
右側はガッツリ恋愛テーマの歌詞ですね。
良い感じに楽曲テーマ毎にトピックが分かれてくれていそうです。
しかし、中にはこんなトピックもありました。
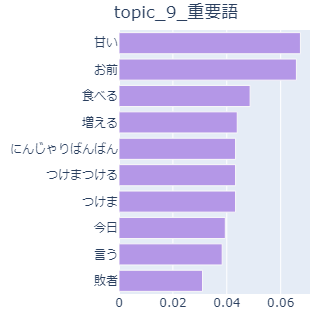
きゃりーぱみゅぱみゅさんに支配されたトピックです。
当然「にんじゃりばんばん」という単語はにんじゃりばんばん(曲)にしか登場しませんし、「つけまつける、つけま」もつけまつける(曲)にしか登場しません。
今回は解析対象が歌詞ということで、作詞者の意図を無視して勝手に表現を統一(キミ、君、きみ⇒君への修正等)するのも憚られたので、 複数の文書に同一の単語が出現しにくくなっています。
そのため、ある特定の文章にしか出現しない単語でもその文章内で複数回登場しているとC-TF-IDF計算において値が高くなりやすいです。
よくよく考えると楽曲の歌詞って、特定の曲にしか登場しないかつ何度も繰り返される単語(造語含む)が結構多そうです。欅坂46の「二人セゾン」、マキシマムザホルモンの「恋のメガラバ」等も歌詞を見ると分かるのですが、登場単語が別のトピックの重要語として抽出されていました。
クラスター内の何曲かに出現するなら全然良いのですが、特定の曲にしか登場しないかつ意味を類推しにくい造語がトピックの重要語として抽出されてしまうのは極力避けたいですね。。。
今回は単語の出現頻度の平方根を取ってTF値の抑制を行うのと、クラスタリング時のパラメータ調整で最終的に下記のようなトピックに分かれました。
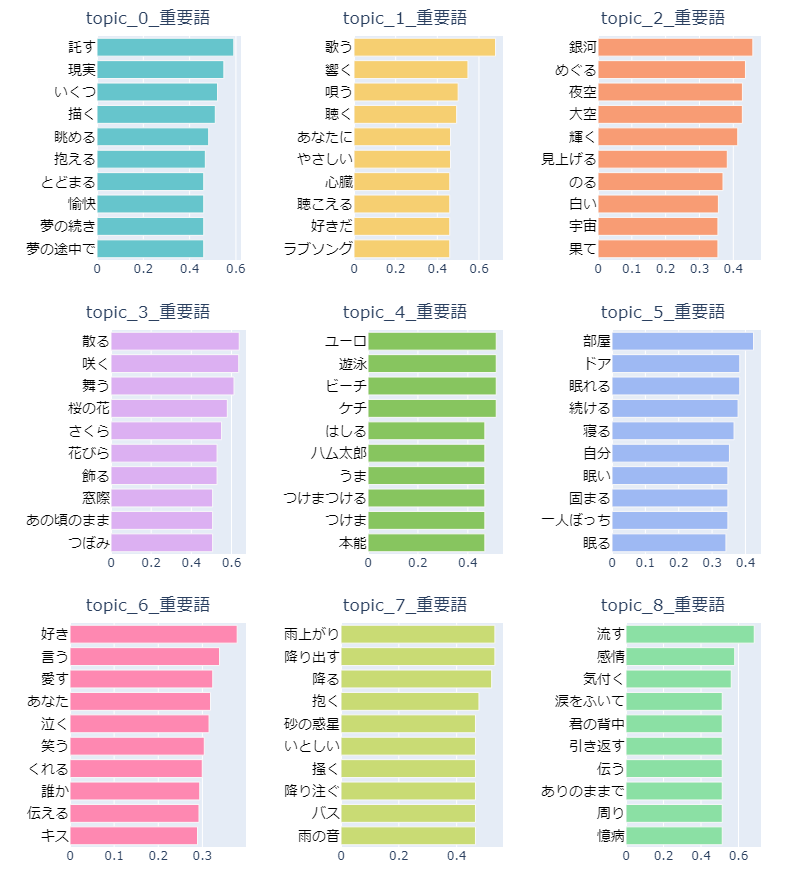
先ほどお見せした造語が多く登場する曲はトピック4にそこそこ集中的に割り当てられたので、トピック4の重要語はかなりカオスな状態になっています(笑)
その他のトピックを見ると、トピック0が夢や未来がテーマのトピック、トピック1が歌がテーマのトピック・・・と、良い感じに歌詞テーマ毎にトピックが分かれてくれた感じがします!
これなら解析対象の楽曲がどのような歌詞テーマでグループ分けされたのか、サクッと把握することが出来そうです。
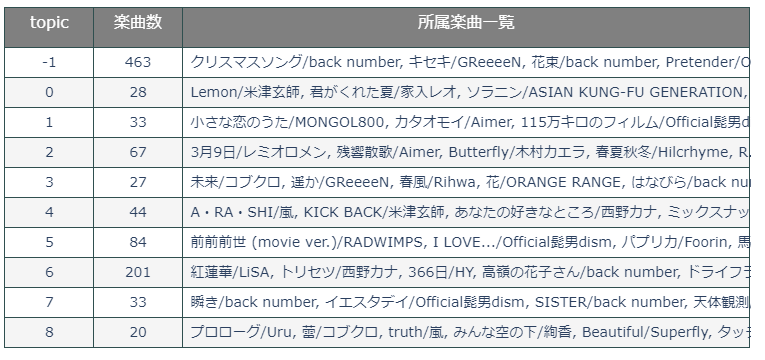
BERTopicのメインのアウトプットは上記のトピック別重要語一覧ですが、他にも
○各トピックに割り当てられた文章の数と内容の一覧(歌詞は載せれないので楽曲タイトル表記に)
○意味的な近さと所属文書数によるトピックのマッピング結果
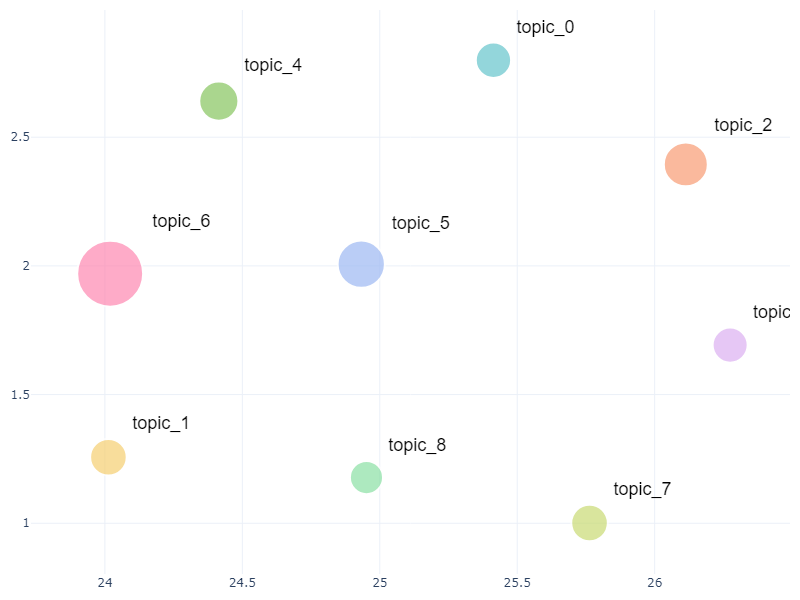
等々色々あります。
トピックに所属する楽曲数を見ると、トピック番号「-1」つまり仲間外れに分類された楽曲の数が結構多いので、パラメータ調整でここの数を減らすよう調整してみても良いかもしれません。
このあたりの調整は先ほども書いた通り、都度アウトプットを確認しながら良い感じの示唆が得られるよう、地道にトライアンドエラーですね。
今回はそこそこいい感じにトピック分類が出来たのでこのあたりで満足して、次にLDAとの結果比較を行ってみます。
ここまでBERTopicによる解析の結果を見てきましたが、ここでノーマルトピックモデル代表のLDAでも同じデータで解析を行って結果を比較してみましょう。
BERTopicでの解析に使用したものとまったく同じTokenizerでの形態素解析、同じトピック数でモデル化を行った結果、下記のようなトピックが得られました。
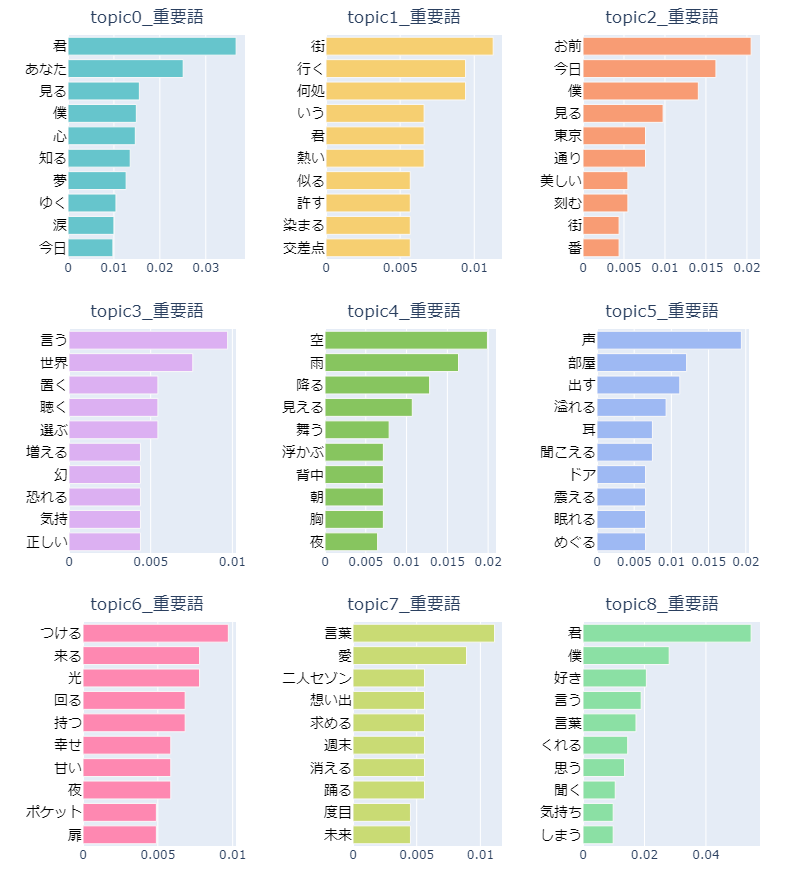
BERTopicと比較して、各トピックの単語の一貫性が無くなり、何に関するトピックなのかわかりにくくなってしまった感じがします・・・。
多様な文章・単語に対する対応力、トピック分類の精度の差が如実に出た印象です。
例えば「桜、蕾、散る」といった単語があった時、BERtopicの場合だと単語の意味的な関連性、類似性をベクトルとして得られているので、これらの単語が登場する文章が同じクラスに配置されるよう働きかけてくれますが、LDAの場合は、単語同士が特定の文章内に一緒に登場するかどうかでしか関連性を見出せないため、今回のような単語表現が多彩なデータへの対応が難しくなります。
また、BERTopicの場合はトピック分類においてHDBSCANを使用するため、「どのクラスタにも属さないクラス」が存在しており、そのおかげで無事にクラス分け出来たグループに関しては余計なものが入り込みにくい、言うなれば、より「純度の高い」トピックを抽出しやすくなっています。
LDAの方は生成モデルになるため、上手くデータにフィットするモデルが出来た時の解像度が非常に高く、構造把握に優れるというメリットがありますが、今回の比較結果を見るにより広範なデータに対して一定以上の結果が出せるという点でBERTopicは既存のトピックモデル手法を大きく凌駕しているなと感じます。
次は少し発展的な、時系列でのトピックと単語の移り変わりの可視化です。
今回は歌詞データを2010年以前の曲、2010年代前半の曲、2010年代後半の曲、2020年代の曲の4時刻に区分けしてみました。
冒頭で少し触れたDynamicTopicModelでは、実際にトピック分布と単語分布の生成パラメータを2時刻分用意し、1時刻前の分布からの正規ノイズにより現在時刻の分布を生成するという流れで時系列での影響を表現していますが、BERTopicでは通常の流れと同じようにC-TF-IDFの算出まで終わらせ、その後、時刻毎に算出したC-TF-IDF値のチューニングを事後的に行うことで時刻間でのトピック、単語の推移を表現するようになっています。
チューニングは割と単純で、まず全文書を対象にして算出したC-TF-IDF、各時刻に属する文章を対象にして算出したC-TF-IDFをそれぞれ用意し、各時刻のC-TF-IDFに対し
①全文書のC-TF-IDF値との平均を取る
②1時刻前のC-TF-IDF値との平均を取る
という手順になっています。
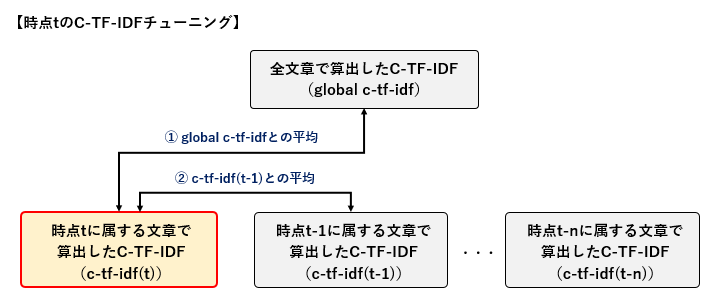
①で全体のC-TF-IDF値と各時刻のC-TF-IDF値が大きく乖離してしまうのを防ぎ、②で時刻間の影響を入れ込むという流れですね。
あくまでデフォルトの計算仕様なので、もし時刻による影響を強めたいなら1時刻前と平均を取るときに前時刻の重みを強めた加重平均にする等、カスタマイズは自由です。
今回は特にカスタマイズはせず、デフォルトの計算仕様で行きます。
では、トピックの推移の確認です。
代表例として、先ほどの結果で断トツで所属楽曲数が多かったトピック6(恋愛テーマ歌詞)の重要語の移り変わりを表示します。
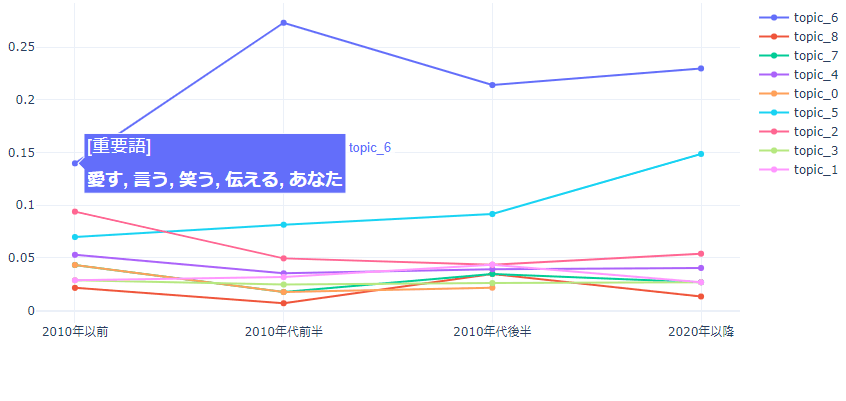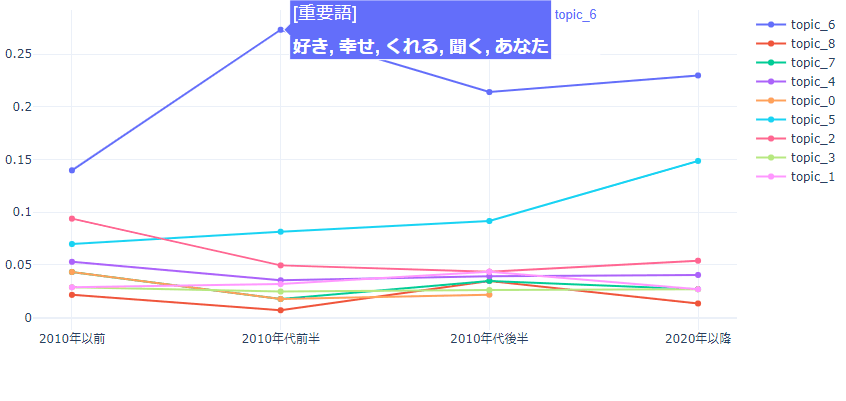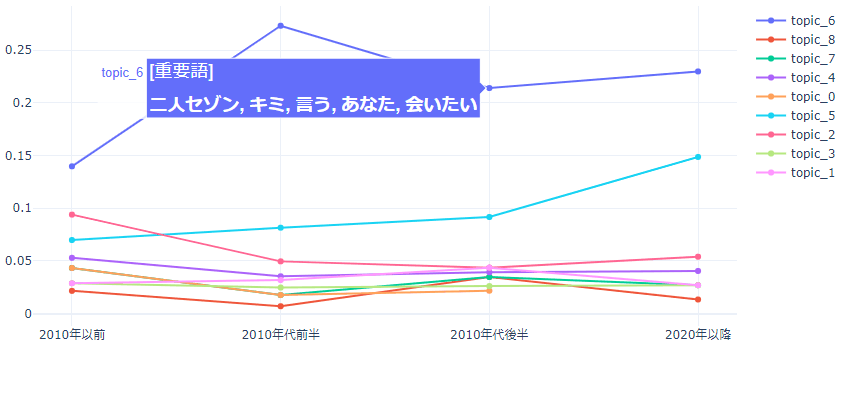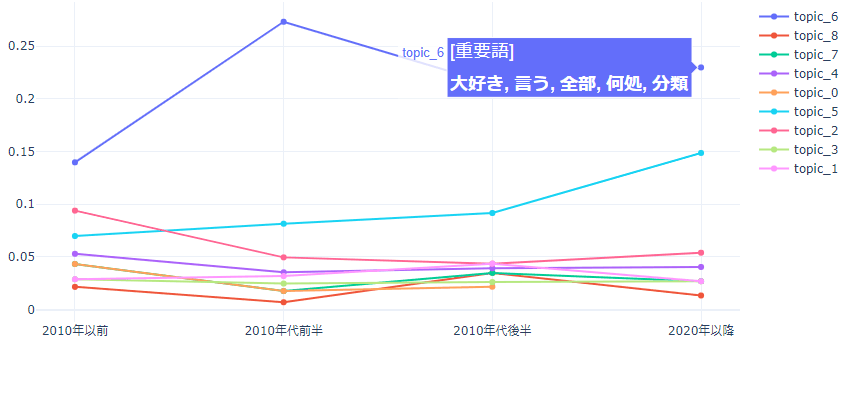
縦軸の値はその年代に属する楽曲のうち各トピックに所属する楽曲数割合です。
恋愛歌詞テーマの楽曲は2010年代前半がピークのようです。
「愛す、好き、大好き」など、年代毎の重要語から言葉遣いの変化も見られて中々面白いですね。
時系列毎に文章を分けるため本来ならもう少し文章数が欲しいところですが、各トピックに所属する文章の数や重要語の遷移から簡単にトレンド傾向等を把握することが出来そうです!
うーん良い感じですねぇBERTopic
もっと色々試してみたいですが、長くなってきたので今回の解析はこの辺までにしておきましょう。
BERTopicによる文章解析の流れをお届けしました。
実際にやってみた感想としては、色々出来て高性能!
これに尽きます。
各ステップでのカスタマイズの幅も広いですし、最初に文章ベクトルという形で数値データを得ているので、やり方次第で欲しいアウトプットを色々な形式で出せそうです。
何でも出来るとまでは言わないですが、公式Githubでも本当に色んなパターンのタスク、アウトプットが紹介されていて、BERTopicの汎用性の高さが伺えます。
勿論LDA等の既存のトピックモデル手法も優れた手法なのですが、実ビジネスでの様々な形式のデータに対する対応力という部分を考えると、今後はまずBERTopicに触手が伸びそうな、それぐらい使い易くかつ強力な手法だなと感じました。
また何か面白そうな解析ネタがあったら、BERTopicの別タスクも試してみようかなと思います!
ではでは!





