

お久しぶりです!sodaエンジニアの國田です!!
相変わらず生成AIが楽しい今日この頃、今回もまたStable Diffusionを使って実験してみたいと思います。
Stable Diffusionでは、ユーザーが入力したテキストを使って画像生成を行っています。
実際の生成過程において、テキストが生成モデル内部で、どのように処理されているのかご存知でしょうか?簡単にユーザー入力のテキストの流れを振り返ってみましょう。
(Stable Diffusionの技術的な概要についてはこちらの記事でざっくりと説明しています。また、2023年6月現在、私が執筆している雑誌記事においても、連載中で詳細を掘り下げながら解説しています。)
まず、Stable Diffusionの基本的な原理は、以下のgifのように、ノイズのかかった画像からノイズの除去を行い、最終的に美麗な画像を得ることにあります。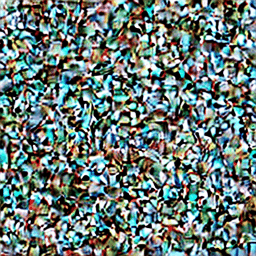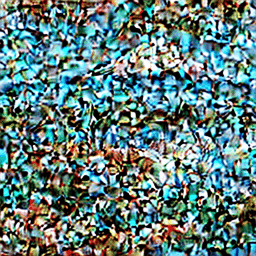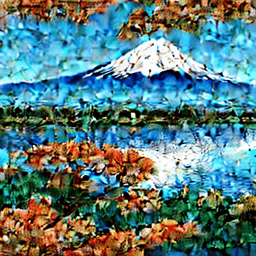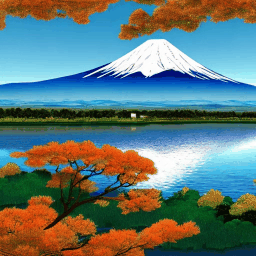 この過程において、Stable Diffusionでは、ノイズ画像をノイズ除去モデルへと通過させるのですが、ここを1回通過するだけで、いきなり美麗な画像が得られるわけではありません。1回だけの通過では、全てのノイズを一気に除去できないため、上のgifのようにノイズの量を少しずつ減らしながら、数十回(20~50回程度)通すことで、美麗な画像を得ています。
この過程において、Stable Diffusionでは、ノイズ画像をノイズ除去モデルへと通過させるのですが、ここを1回通過するだけで、いきなり美麗な画像が得られるわけではありません。1回だけの通過では、全てのノイズを一気に除去できないため、上のgifのようにノイズの量を少しずつ減らしながら、数十回(20~50回程度)通すことで、美麗な画像を得ています。
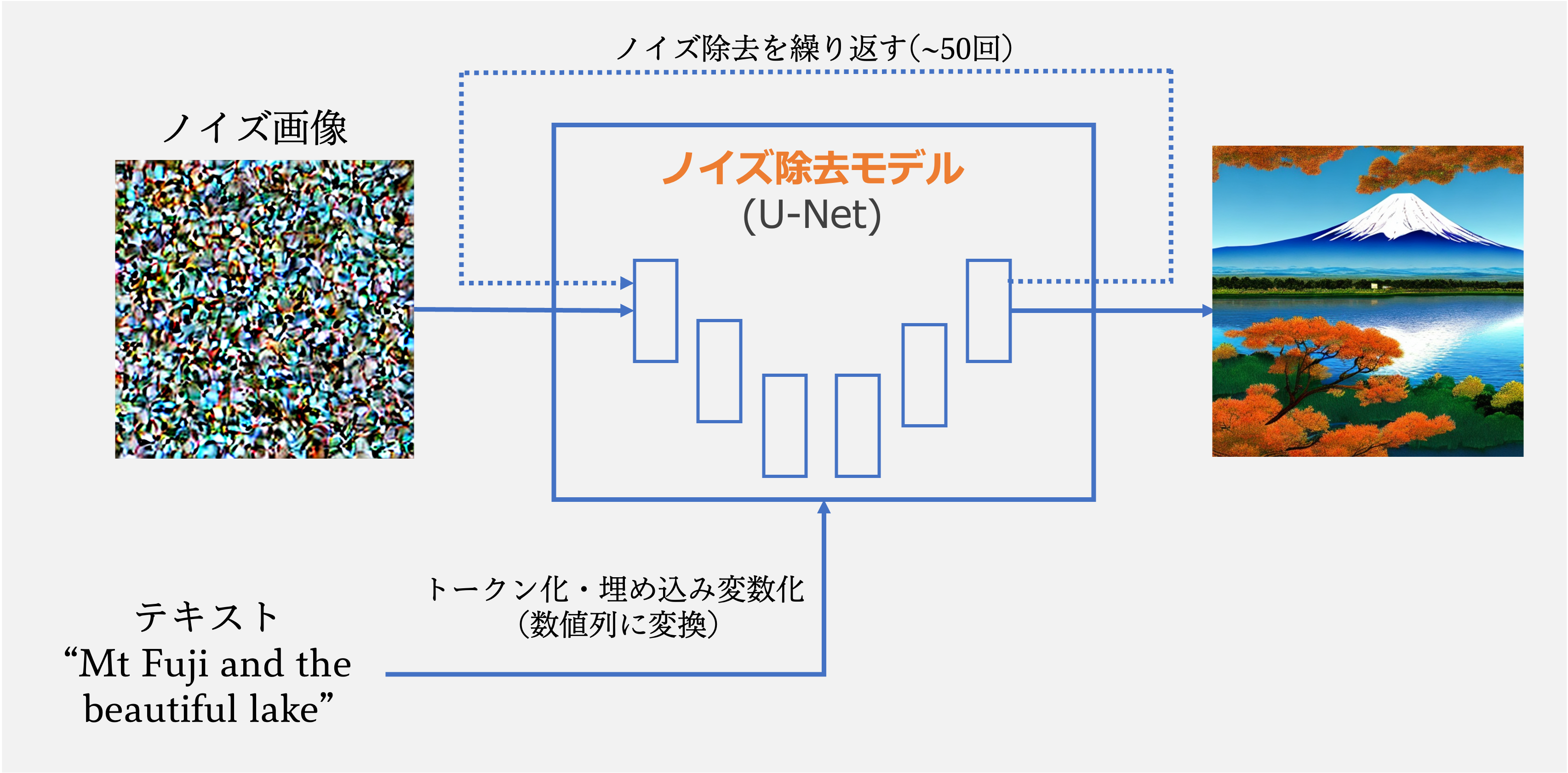
このノイズ除去の過程において、毎回、ユーザーの入力したテキストが渡されます。何故かと言いますと、単純に「ノイズ除去して」というだけでは、AIは除去した後にどんな画像へと変えていけば良いかわからないからです。たとえるなら、直方体の石に彫刻を施す時のようなもので、テキストは、プロの彫刻家が初心者に与える「どこを彫れば良いのか」のアドバイスというわけです。そのアドバイスを受け取り、ノイズ除去モデルは、テキストの内容に近い画像になるようにと処理を施しています。
つまり、ノイズ除去の回数と同じ回数、数十回にわたり、テキストはモデルに与えられています。では、この過程で与えるテキストを変えてみるとどのような画像が得られるのでしょうか?
例えば、ノイズ除去1回ごとに、交互に違うテキストを与えてみます。プロの彫刻家2人が初心者一人に交代で別々の指示を与えていくようなものですよね?きっと面白い画像が得られるのではないでしょうか?
さっそくやってみた。
さて、さっそくやってみましょう!
「犬」→「猫」→「犬」と、交互に異なる指示を出してみました。生成画像は以下です。 驚くべきことに、テキストが毎回変わるからと言って、滅茶苦茶な結果にはならないのですね。犬のような猫のような、絶妙な絵ができあがっています。耳や目は猫っぽく、髭もありますが、鼻・口や全体の印象は犬になっています。
驚くべきことに、テキストが毎回変わるからと言って、滅茶苦茶な結果にはならないのですね。犬のような猫のような、絶妙な絵ができあがっています。耳や目は猫っぽく、髭もありますが、鼻・口や全体の印象は犬になっています。
以前やった、埋め込み表現へのアプローチとはまた違った混ざり方をしているのも面白い点です。それもその筈で、以前は「犬」と「猫」という言葉をあらかじめ数値化した上で、その間にある変数を渡していました。そのため、ノイズ除去過程において完成予想図は常に一緒です。今回はノイズ除去のタイミングごとに「犬に近づけろ」「猫に近づけろ」と毎回異なる指示が飛んでくるため、どっち付かずな絵を生成せざるを得ないという状況を無理矢理作り出しています。
上記の生成過程もgifにしてみました。犬と猫の指示が交互に来るため、どちらの印象も残したままノイズ除去が進んでいるのが見て分かります。
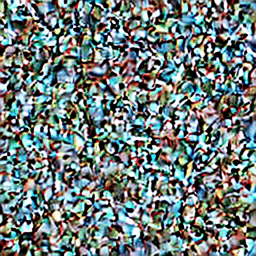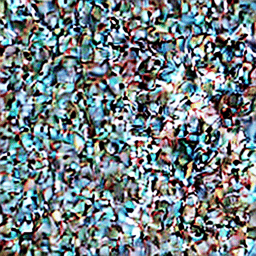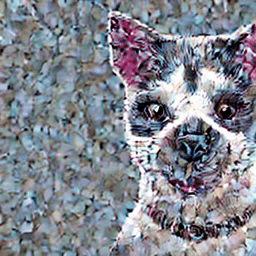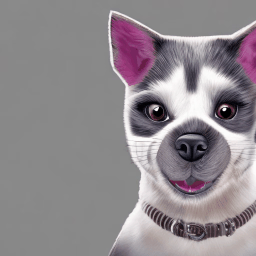
他のパターンも見てみましょう。上記の「犬」と「猫」の例は比較的似通った動物ではあるので、今度は姿の大きく異なる「犬」と「ゴリラ」で交互に指示してみます。 非常にかわいい画像が得られましたね。犬の特徴もよく出て、牧羊犬のようですが、ゴリラと言われても、そこそこ説得力のある仕上がりになっているのではないでしょうか?
非常にかわいい画像が得られましたね。犬の特徴もよく出て、牧羊犬のようですが、ゴリラと言われても、そこそこ説得力のある仕上がりになっているのではないでしょうか?
私は、個人的にゴリラが大好きで、よく「ゴリラってかわいいですよね?」と言うのですが、なかなか共感してもらえません。ですが、この画像のゴリラ(犬?)であれば共感してくれる人も多そうです。
次はこちら「日本人の女の子」と「インド人の女の子」を交互に指示してみます。 やはり、両方の印象が残る女の子になりましたね。さながら、日本人とインド人のハーフのようです。
やはり、両方の印象が残る女の子になりましたね。さながら、日本人とインド人のハーフのようです。
この手法によるメリットは、通常のStable Diffusionとは異なり、指示を1つのテキストプロンプトにまとめなくて良い点です。上記の画像を生成するためには、"Japanese and Indian half girl"などとプロンプトを入力しなくてはなりませんが、Stable Diffusionの性質上、必ずしもハーフの女の子にはなりません。それで生成されるのは、和服を着たインド人かも知れませんし、日本家屋にいるインド人かも知れません。元となっている学習用のデータセット内でハーフの女の子というのが希少である上、Japaneseという単語から連想される表現が非常に多岐に渡るからです。
中間的な表現の探索はここまでにして、応用的なアプローチを考えてみます。例えば、「地球をボールに見立てて遊ぶ猫」を生成したいとしましょう。通常、これをそのままテキストで入力してもなかなか目当ての画像は生成されないです。多くの場合、宇宙空間にいる猫やボールで遊んでいる猫が生成されるだけで、うまい具合に生成されません。
ですが、「ボールで遊ぶ猫」「猫と地球」というテキストを交互に渡してみることで、狙いの画像が生成される確率が一気に高まります。 Stable Diffusionでは、複雑なテキストプロンプトを入れた場合、テキストの後ろにある要素ほど無視されてしまう傾向があります。ですが、この渡し方であれば、テキストの順番をそこまで意識することなく、繁栄したい要素を含んだテキストを2つ用意するだけで良くなります。
Stable Diffusionでは、複雑なテキストプロンプトを入れた場合、テキストの後ろにある要素ほど無視されてしまう傾向があります。ですが、この渡し方であれば、テキストの順番をそこまで意識することなく、繁栄したい要素を含んだテキストを2つ用意するだけで良くなります。
この性質を活かして、1つ実験をしてみましょう。
みなさま、ミケランジェロ・ブオナローティはご存知でしょう。ダビデ像の彫刻家であり、最後の審判等の絵画で有名な画家でもあります。その作品からも分かる通り、彼は筋肉が大好きでした。女性も子供もムキムキに描き、教団からクレームが来たほどの筋肉好きです。
そこで、彼の画風のまま、より強力に筋肉を再現してみることにします。
「ミケランジェロの画風の作品」と「ミケランジェロのボディビルダー」を交互に指示します。できた画像がこちら。
大胸筋の厚さ・上腕二頭と三頭のボリューム・大腿四頭筋のカット、どれをとっても近代の一流のボディビルダーの画像が再現できたように思います。筋肉への讃美歌が聞こえてきそうですね。
まとめ
いかがでしたか?
オープンソースであるStable Diffusionには、様々なカスタマイズで生成画像をコントロールすることができます。
現在、イラスト画像や人物写真画像に特化したモデルが頒布されたり、特定の単語を強調させる手法で画像のコントロールを行うなど様々な手法が登場していますが、本記事のようにちょっとした工夫だけでも、楽しむことができるのが、Stable Diffusionの実に面白い点だと思います。
こういった技術や工夫を組み合わせて、人の頭の中にある概念や思い出などを可視化できるようになる日もそう遠くはないのではないでしょうか?
おまけ
交互ではなく、ノイズ除去の最初のうちはテキストA、その後、ぼんやりと画像の概形が浮かび上がってきてからテキストBに変えるとどうなるのでしょうか?
テキストAを「犬」にした上で、色々と変えてみました。
参考までに「犬」のみで最後まで普通に生成すると以下の画像が得られます。

そして、テキストを変更した場合がこちら。
| 猫 | ゴリラ | 象 | 恐竜 |
 |
 |
 |
 |
概形を保ちつつも、テキストの示す内容にうまく変わっていくのがよく分かりますね。





