

どうも!! sodaエンジニアの國田です!!!
生成AIが熱い!!熱すぎます!!!
これまで、様々な生成AIを紹介してきましたが、ついに大きな動きがありました。
なんとイギリスのAI会社stability.aiがテキストから画像を生成できるAIを一般公開したのです。その名も「Stable Diffusion」。
かつて当ブログでもテキストによる画像生成モデルは取り上げましたが、それよりもはるかにハイクオリティな画像を生成できるAIのようです。
試しに私も「Stable Diffusion」で画像を作ってみました。
「Zombies and ghosts enjoying swimming at the beach(ビーチで水泳を楽しむゾンビと幽霊)」

「clown on the pirate ship(海賊船に乗ったピエロ)」

それぞれ、単純に英文テキストを入力しただけですが、ほぼ実用レベルの画像が生成できているように思えます。
「Stable diffusion」はリリース直後から日本でも様々なメディアに取り上げられており、SNS界隈でも「AIで生成してみた」系の投稿がかなり多く見られました。その圧倒的なクオリティもご存じの方も大勢いらっしゃることと思います。
また、Stable Diffusionがすごい点はソースコードや学習済みモデルも全世界に公開している点。これまで一部の研究者やエンジニアしか触ることのできなかったAIがとうとう誰でも触れるような時代が到来したと言えるのではないでしょうか。
いつもでしたらこの流れで「Stable Diffusion」の実験を行うのですが、「生成してみた」系の記事は既にかなり多くの方によって書かれています。そのような内容は他の記事にお譲りし、当ブログでは、「Stable Diffusion」の技術的な内容について面白おかしく解説できればな、と思います。いつも通り、「数式なし」「分かりやすく」「簡潔に」を心がけて説明しちゃいますよー!!
ちなみにですが、「Stable Diffusionを試してみたい!」という方、サービスサイトで登録をするか、簡単に無料お試しがしたいだけであればこちらのサイトで試すこともできます。
Stable Diffusionはどんなモデル?
先に述べましたように、Stable Diffusion はテキストから画像を生成するモデルです。
「Diffusion Model」と呼ばれるモデルがStable Diffusionのベースになっています。
Diffusion Model
では、そのDiffusion Modelとは一体なんなのでしょうか?
生成モデルではGANが有名ですよね?GANとは生成器と識別器が互いに監視し合いながらモデルを発達させていくモデルのことです(詳しくはこちら)。
ただ、Diffusion modelはGANとは全く異なる機構の生成モデルです。識別器を必要とせず、生成に使うのはノイズ画像と呼ばれる砂嵐みたいな画像です。
ノイズ画像から綺麗な画像を生成すると言いますと、大変なように思えます。ぐちゃぐちゃに塗りつぶされた画像から綺麗な画像を生成するので、途方もない作業になるのは想像に難くないでしょう。
では、どうやるのかと言いますと、初めに逆の過程を考えます。
つまり、綺麗な画像をノイズに変換するということを考えてあげます。
以下の図をご覧ください。
上図の左から右に向かう過程(綺麗な画像→ノイズ)を再現することは明らかに簡単にですよね?個々のピクセルを適当にずらしていくだけです。このプロセスを何回も繰り返してしまえば、最終的には元の画像の片鱗も残さない完全なノイズ画像ができあがります。
勘の良い方はここで気づくかもしれませんが、綺麗な画像→ノイズができるということは、逆もできるということです。上の図の通り、綺麗な画像→ノイズ画像の過程は何回もノイズ化のための処理を繰り返しています。つまり、ノイズ画像からノイズになる1個手前の画像の再現はできるし、1個手前の画像があれば2個手前の画像も再現できます。これを繰り返すことで、ノイズから元の綺麗な画像を再現しようというのがDiffusion modelです。
ちょっと難しい話になりますが、ノイズ化する過程では、どの程度ノイズ化するか?みたいな確率変数が与えられますので、その確率を計算に入れることでノイズの除去が可能になります。
Diffusion modelでの画像の作成例を見てみましょう。以下はゴリラの画像を生成させてみました。
ご覧のように、本物画像と見紛うレベルの画像が生成できていることがお分かりになると思います。GANでの生成画像は画像の逆畳み込みを利用しているので、連続する線が歪に歪むことがあるのですが、Stable Dissusuionでは画像の部分部分に計算リソースを割いているため、被写体の形状がすごく自然に映ります。
さて、このDiffusion Modelですが一つ問題があります。ノイズ除去と単純に言ってはいるものの、「画像全体にノイズをかける」なんてメチャクチャ大変ですよね?画像サイズと同じ大きさのノイズ画像をいちいち用意するなんて、画像サイズが大きければ大きいほど計算量は膨大に膨れ上がり、メチャクチャ時間がかかります。
そこで登場したのがLatent Diffusion Modelです。
Latent Diffusion Model
Latent Diffusion Modelでは、大きな画像を圧縮し、潜在変数と呼ばれる数値の羅列にまとめてしまいました。以下の図をご覧ください。

見ての通り、画像を小さな潜在変数へと圧縮するエンコーダーと、変数を画像に戻すデコーダーを取り付けました。すごく単純に見えますが、効果は絶大。これにより計算量を大幅に小さくすることに成功しています。
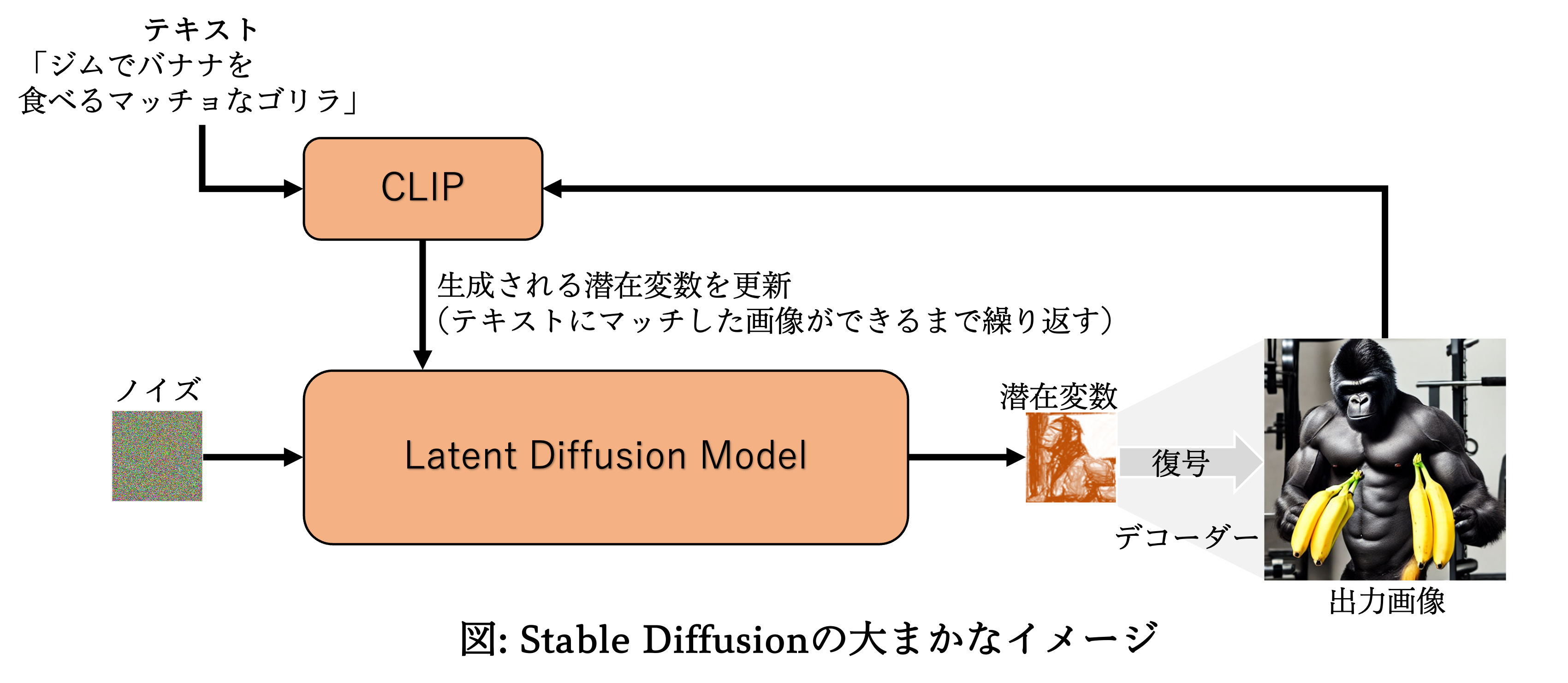
以上がStable Diffusionの画像部分の仕組みです。では、続けて入力されたテキストをどのようにして画像の出力へと変えているのか?という部分についてお話しましょう。
CLIP
テキストと画像を結びつけるには、CLIPと呼ばれるモデルを利用しています。
CLIPは「画像」と「画像の説明文」を学習しており、これを使うことで、ある画像に対し、その説明文がどの程度合っているかを出力することができます。(これを難しい言葉で画像とテキストの類似度と言います。)
例えば、「たわわに実った赤いリンゴ」という説明文と「リンゴの実がたくさん宿った木の写真」はよく似ているという評価が得られ、同じ説明文に対し「猫のイラスト」を渡したり、「女優の顔写真」を渡したりするとあまり似ていない、合っていないという結果が数値(=低い類似度)で出力されるというわけです。CLIPにつきましてはこちらでも解説していますので、気になった方は是非ご一読ください。
Stable Diffusionでは、このCLIPモデルをLAION-Aestheticsと呼ばれるデータセットを使って学習させたものを利用しています。 LAION-Aestheticsは「芸術性」や「美しさ」という観点に基づいて、人間が画像とテキストをそれぞれ評価し、合格したもののみで構成されたデータセットです。Stable Diffusionのようなテキストベースで絵を生成するAIのために最適化されたデータセットと言っても良いでしょう。
CLIPによるテキストからの画像生成では、以下のような流れを考えます。
① 生成モデルで適当に画像を⽣成
② 「⽣成された画像」と「ユーザーが入力した画像の説明文」をCLIPで⽐較
→ 類似度(画像とテキストがマッチしているか?)を計算
類似値を誤差として誤差逆伝播を行い、類似度が大きくなる潜在変数を探してくる
③ 更新された入力を⽤いて、生成器に新しい画像を⽣成させる。
④ 類似度が⼗分に大きくなるまで②、③を繰り返す。
以下、Stable Diffusionの構造を図に示します。(簡単のため、かなりざっくりイメージで示しています。アテンション機構やU-netといった細かい機構について知りたい方は原論文[1]をご参照ください。)
以上、今回はStable Diffusionのコア技術について説明しました。
Stable Diffusionの発表以降、生成AIに関連したサービスも次々と加速度的に展開されているように見受けられます。
Stable Diffusionのような生成AI自体が、アーティストやデザイナーの仕事を代替するというようなことはすぐではなさそうですが、その時代の到来はそう遠くないでしょう。
「AIが仕事を奪う」と言うとマイナスイメージが付きまといますが、AIとの差別化のためにも、我々人類の仕事はもっと高付加価値の仕事へと進化していくと思うのです。
次はどのような分野にAIが進出してきて、私等の社会はどのように変わるのか、本当に楽しみですね!
参考
[1] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser and Björn Ommer, High-Resolution Image Synthesis with Latent Diffusion Models., 2021 https://arxiv.org/pdf/2112.10752.pdf





