

こんにちは!
sodaの古橋です。
ブログ投稿の間隔が結構空いてしまいまして、気付けば世間では阪神タイガースが18年ぶりとなるリーグ優勝を決めていました。
久々の優勝ということで大いに盛り上がっていますが、我が敬愛する中日ドラゴンズは2年連続の最下位争いを繰り広げているという状態で、私は少々センチな気分になっております。。。
さて、センチと言えばセンチメント(≒感情)分析というものが世の中にはありますが、実際にやったことがある方も中にはいるでしょうか?
文章を読み込んでポジネガ判定をしてくれるアレですが、個人的には感情分析単体で何か業務上のアウトプットを出したという記憶があまりなく、どうにも使い所が難しい印象があります。
ポジネガ抽出や比率の集計自体が目的のアドホックな分析案件であれば勿論それで充分なのですが、「雑多な文章から良い感じに意見を集約・分析したい」みたいなシチュエーションの場合、感情分析しましたーだけでは結果として物足りなく感じてしまうこと、あるのではないでしょうか?
っというわけで、今回は感情分析の活用方法を見出すための実践記事です。
以前ブログにも投稿したSLDA(SLDAでレビュー解析)を使って、感情分析の結果をSLDAの教師データとして転用することで、文章データ単体から感情係数値付きのトピックが抽出出来るのではないかというのが今回の試みになります。
ではでは、早速やってみましょう。
さて、まず始めに今回やろうとしている内容を整理するとこんな感じになります。
1.文章データを用意して感情分析を行い、ポジネガの確率を抽出する
2.ポジネガの確率値をSLDAの教師データとしてセット
3.文章データと設定した教師データを使いSLDAでモデル化を実行
4.感情係数値付きのトピック分類を得る!!
物体検知や画像認識の分野でオートアノテーション(自動教師ラベル付与)は良く聞きますが、SLDAの教師データとして感情分析でアノテーションしたものを使ってしまおうという感じですね。
SLDAについて簡単に復習すると、LDAの生成過程に文章のトピック分布を使用した線形重回帰の項を追加し、教師データの予測についても同時に満足させるようなパラメータ推定を行う手法でした。今回は感情の予測確率を教師データに用いるということで分類モデルで構築するのが自然な気もするのですが、せっかくの確率の大小という情報を捨ててしまうのも勿体ない感じがします・・・。
予測確率が大きい=基本的にはよりその感情の度合が大きいとも見なせると思うので、ここは一度回帰モデルにあてはめてみることにしましょう。
以前のブログでは鬼滅の刃の映画レビューデータを使用しました。
今回は教師データ無しで文章のみから情報を抽出するのが目的なので、SNS等から分析用にデータを引っ張ってきても良いのですが、感情分析の予測結果を土台にするというなかなかに不安定な内容にもなっているので、そこの精度はある程度担保しておきたい所です。
初めての試みにもなるので、今回は敢えて前と同じ鬼滅の映画レビューデータを使い、実際のレビュー数値(≒正解データ)と比較して感情分析の精度がある程度しっかりしているかどうかを確かめながら慎重に進めてみようと思います。
最終的には文章データだけを使って前回と同じようなトピックの分類結果を得られるのが理想です。
ちなみに前回のトピック分類結果はこんな感じでした。
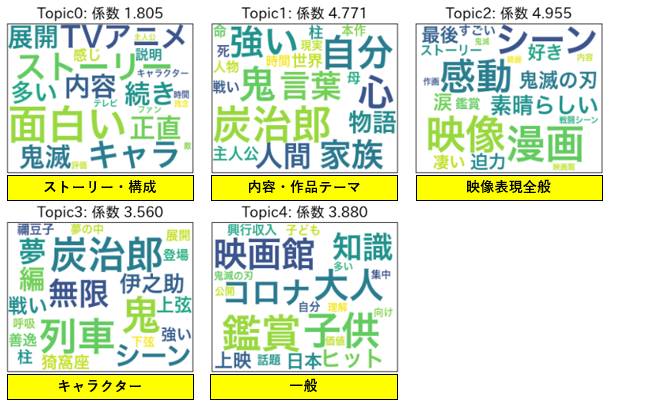 ※あらためてモデル化したので係数値等が微妙に前回と異なります
※あらためてモデル化したので係数値等が微妙に前回と異なります
単語を見てると鬼滅フィーバーの頃を思い出して、今度はノスタルジックな気分になってきました。
今日はなんだか良い感情分析が出来そうな気がします。
では早速、文章を感情分析にかけて結果を抽出します。
今回はAzure Cognitive Services for Languageを使用して感情分析を行いました。
言語処理関連の様々な機能が搭載されたクラウドベースのサービスで、感情分析以外も様々な機能が搭載されています。中身はTransformerベースのモデルとなっているようです。
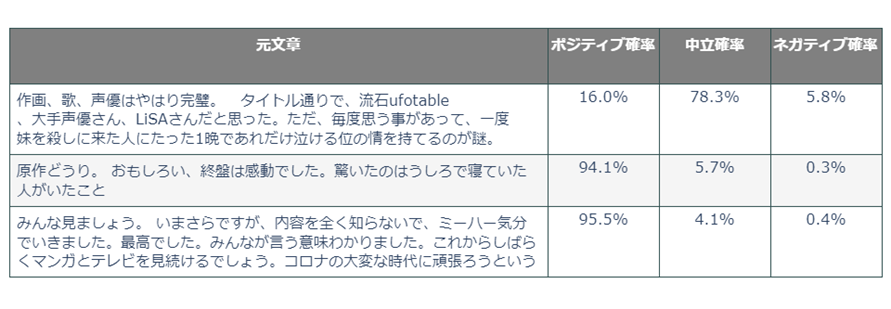
感情分析を行うと、下図のように「ポジティブ」「中立」「ネガティブ」の各ラベルに対し合計1となるよう確率値が振られます。
ポジティブorネガティブと予測されたレビュー数の時系列での推移が下記です。
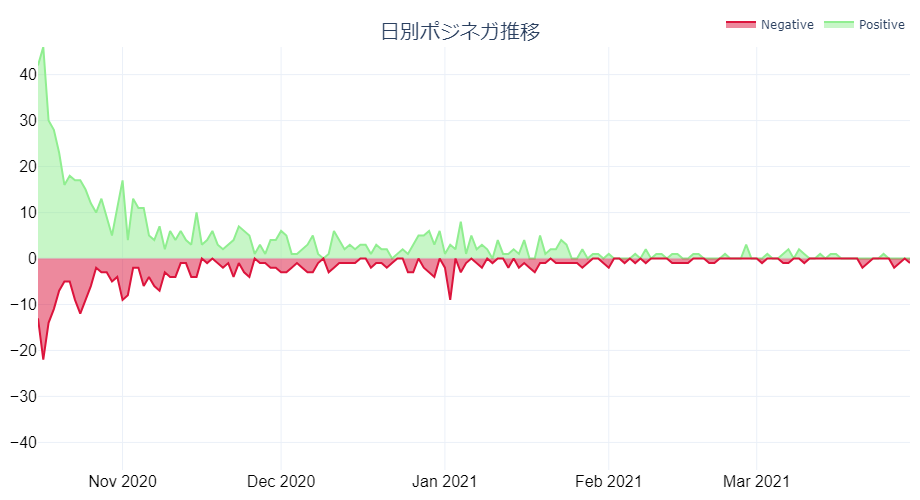
実際の☆2以下のレビュー数は全体の10%以下ですが、グラフを見るとネガティブ予測が結構多くなってしまっていそうです。次ステップの精度確認で細かく見て行きましょう。
精度確認のためには正解データを準備して予測と突き合わせる必要があります。
元の数値レビューは☆0.5~☆5までが0.5刻みで存在しているので、☆4以上をポジティブ、☆2以下をネガティブ、間を中立という形で正解ラベルとして割り振り、予測結果と照合してみます。
多値分類の場合も2値分類と同じようにAccuracy(正解率)、Precision(適合率)、Recall(再現率)、F値を主な評価指標として見て行きますが、全ラベル分を一度に見ることは出来ないので、positiveラベル/それ以外のラベルというような形で個別のラベル毎に評価指標を算出します。
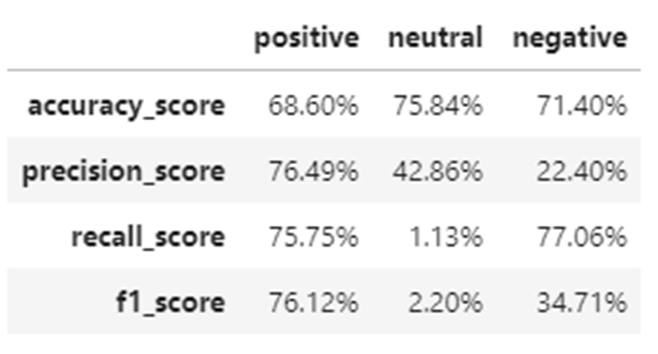
ポジティブラベルについては精度よく推定出来ていそうですが、ネガティブ、中立レビューの精度が心許ないですね。中立の再現率、ネガティブの適合率がかなり低くなっているので、特に☆2.5~3.5のレビューをネガティブ感情と予測してしまっているパターンが多そうです。
さて、数値を見ると精度は微妙・・・中立ラベルなんかは使いものにならないレベルに感じてしまいますが、これは感情予測の精度が悪いというよりも、正解とした数値レビューの付け方が個々人によって異なっていることにも起因しているかもしれません。
レビュー内容的には完全にネガティブだけど、周りの評価が高いから取り敢えず☆は3つという付け方をする人もいるでしょうし、そもそも大体の映画が☆3以上なので基本的に☆3以上の範囲でしか付けないというように全体のバランスも考えて点数を付ける人、反対に良かった映画は☆5、悪かった映画は☆1というような極端な付け方を好んでする人も中にはいるでしょう。
このように個々人で数値に対する認識の差異があると、結局同じ☆3でもどれくらいの感情で☆3を付けているかが人によって変わってきてしまうという問題ですね。

上記レビューは一例で、全て☆3が付けられたレビューですが、文章から受ける印象としては実際の☆の数よりも感情分析の結果の方が寧ろ納得感があります。
前回分析した際は実践例ということでここまで言及していませんでしたが、何等かのレビュー数値をSLDAの教師データとする場合、本来であれば☆5:大変良かった、☆4:良かった・・・のように数値に対する基準が決められたレビューを使うのが望ましいかと思います。
今回のように個々人でスコアの基準に差異がありそうな場合は、敢えて実際のスコアを使わずに感情分析をかませてからSLDAでモデル化をした方が、トピック分類の精度として良くなるというケースもあるかもしれません。
・・・つらつらと感情分析結果を使う正当性を書き連ねましたが、っとはいえ現状の評価指標のデータをそのまま教師データとして使うのも不安なので、今回は中立と判定された文章は省いてモデル化してみようと思います。
データ数に余裕があるのであれば、さらに閾値を決めて、ある程度大きな確率値でポジティブorネガティブと予測された文章に絞っても良さそうです。
今回はデータ数1000程度とやや心許ないので、ポジティブ、ネガティブと判定された文章は全て使います。
感情分析の結果が得られたので、次にSLDAでのモデル化です。
今の状態だと得られた予測値が各感情ラベル毎の3つに分かれているため、1つに集約してSLDAの教師データとして活用します。
方法は色々ありそうですが、今回は単純に「ポジティブラベルの予測確率-ネガティブラベルの予測確率」にしてみようと思います。
結果、教師データとして-1~+1までの範囲の数値で1に近いほどポジティブ、ー1に近いほどネガティブというものが得られます。
では、文章&スコアの準備が整ったので、実際にSLDAでモデル化した結果を見て見ましょう。
結果の比較を行うため、トピック数は前回と同じ5です。
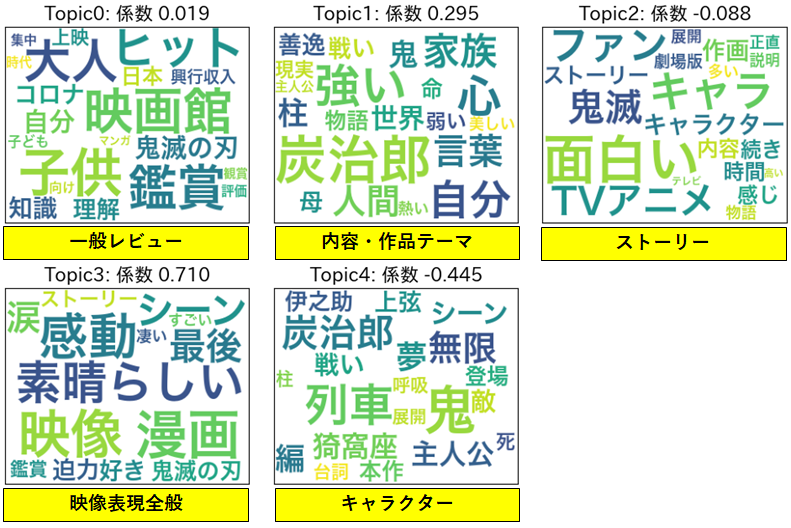
トピックの分類はほぼ前回と同じような形になりました。
係数値についても映像や作品テーマのトピックが高いという部分は同じですが、ストーリ-のトピックよりもキャラクター関連のトピックの方が係数値が低くなっているという点だけ前回と結果が異なります。
これに関しては、実際のレビューを見るとダイジェスト的なネタバレ(「〇〇と△△が戦って死んでしまって悲しい」というような)を書いている人も結構多いので、そのあたりが感情分析ではネガティブとして捉えられやすく、このような結果になったのかなと思っています。
先ほど記載した通り、実際のレビューである☆の数を教師データとして使うのが必ずしもトピック分類にとって良いとも限らないですし、かといって感情分析の結果も少なからず誤分類は存在するため、どちらの結果の方がいいというのはなかなか甲乙つけがたいですね・・・
ただ、スコアの教師データが無い状態から前回の結果とある程度は近しいものを得る事が出来たので、個人的にはなかなかに実用の可能性も感じられる結果になったのではと思っています。
スコアデータがない文章データだけの時は勿論、スコアデータがある時でも、より良い解析のための一手段として試してみたいところです。
最後に、今回の分類結果を2次元マッピングしたものがこちらです。
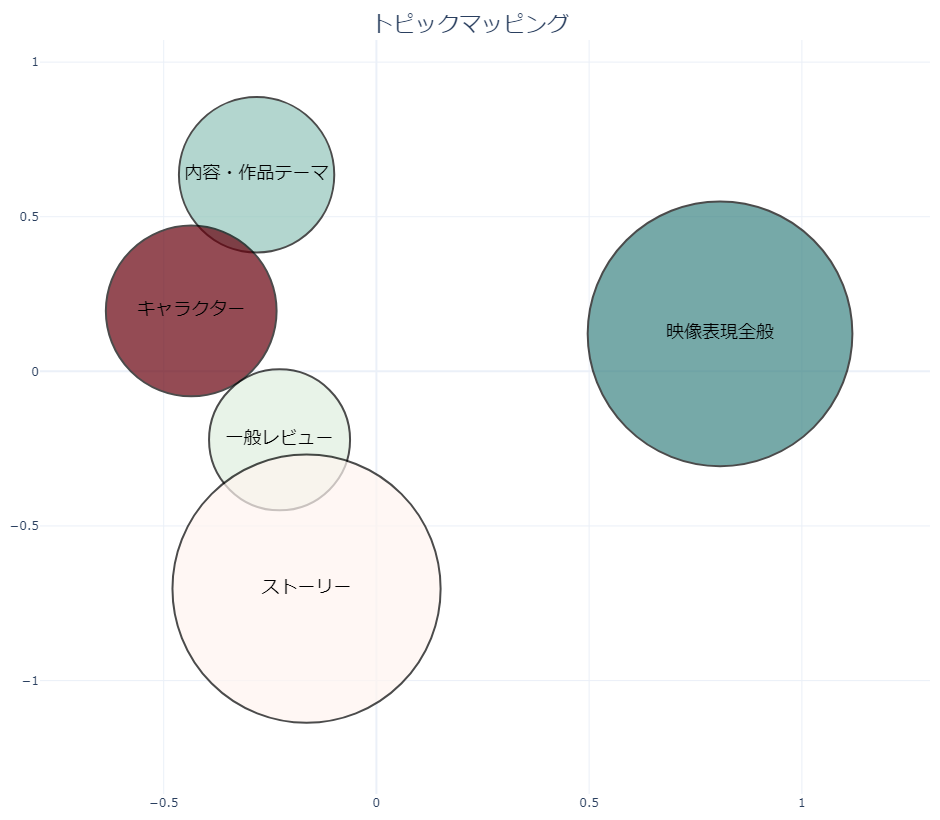
ざっくりと
・円の大きさがそのトピックについて言及されたレビューの数
・円の配置がトピック間の関係性
・円の色がトピックの感情係数(緑が+、赤が-、色が濃いほど絶対値大)
になるようにしています。
このようにマッピングすることで、一目で結果を俯瞰出来たりするので便利です。
映像表現のトピックだけ他と離れて配置されていますし、それだけ映像についてのインパクトが大きく、そのトピック単独で高評価をしている人が多かったということでしょう。
感情分析の活用方法として、SLDAと組み合わせた感情係数値付きトピック抽出を行ってみました。
いかがでしたでしょうか!
感情分析の精度さえある程度しっかりしていれば、教師データ無しで文章データだけから、係数を感情ラベル予測値としたSLDAのアウトプットを出せそうです。
SNSのコメント等、レビューのない文章データからでも、単純なテキストマイニングやトピック分類からもう一段踏み込んだ洞察が得られる期待が持てますね。
SNSであればいいね数やインプレッション数等が教師データとして使えるのでは?とも考えられそうですが、それはそれで文章内容とは関係ない投稿者の知名度・人気度によるバイアスであったり、そもそも分布がSLDAの回帰式に即していないという問題も出てきそうです。
そのような状況であったり、先に挙げたように数値の付け方の基準が個々人で大きく異なっていそうな場合であれば、今回の感情分析+SLDAというやり方も十分候補に挙がるではと思います。
注意すべき点としては、やはり感情分析の精度面でしょうか。
実際は正解の数値レビューが無い、文章だけの状態から実行する想定なので、目視等でちゃんと分類出来ていそうかある程度は確かめておかないと、ガッツリ間違ったトピック分類結果を出してしまいそうなのが怖い所です。
言語モデルも進化スピードが非常に早く、このような分析にもどんどん取り入れていけそうなので非常に楽しみなのですが、精度の高いモデルでも慢心することなく、慎重に分析を進めていくことを心掛けたいですね!
ではでは!





