

どうも!sodaエンジニアの國田です。
突然ですが、皆さん、画像生成AIは楽しんでいますか?
私も最近、Nano Banana Proでいっぱい遊んでいます。コンテキストの理解力が非常に優れているので、楽しいですよね。AIエンジニアとしても興味津々です。
・・・はい? なになに?
「AIエンジニアなのに、中身や技術詳細の公開されないモデルでばかり遊んでて良いのか?」
「AIエンジニアなら、もっとエンジニアらしいモデルを触りなさいよ!」
「ローカルモデル触るのやめたの?」
ですって...?
ふふふ...私が既製品ばかりで遊んでいると思いましたか?
残念ながら大間違いです!きちんとエンジニアとして、オープンソースモデルも弄り倒していますとも!!
と、いうことで、今回は久しぶりにローカル画像生成モデルを紹介してみたいと思います。
Qwen-Image-Edit-2511
今回紹介しますのは、この画像生成モデル【Qwen-Image-Edit-2511】(Wu et al., 2025)です。
Qwen-Image-Edit-2511 は、中国の大手テクノロジー企業 Alibaba(アリババ) が開発・公開している「画像編集特化型のAIモデル」です。2025年12月に公開されました。
Qwenシリーズは、言語モデル(LLM)や視覚言語モデル(VLM)など、多岐にわたる大規模モデル群として提供されています。
公開はオープンソース形式で行われており、ライセンスとして商用利用可能である"Apache 2.0"が用いられています。(嬉しい!!)
どんなモデルなの?
Qwen-Image-Edit-2511は、画像を元に「編集」指示を理解して加工・変換する能力に特化したAI モデルになります。具体的な特徴としては、
- 自然言語指示による画像編集:入力画像に対してテキストで修正内容を指定し、それに基づいた編集が可能
- 高い一貫性(Consistency):人物の顔や特徴、複数人物の配置など、元のイメージを壊さず編集する性能が高い
- マルチ画像編集:複数枚の画像を同時に処理し、合成編集なども可能
つまり、Nano Banana ProやGPT-Imageでやっていたテキストベースの簡単な指示で、画像の編集を指示することができてしまいます。なんとも贅沢なモデルです。
(ちなみに、このQwen-Image-Edit-2511「お手軽にモデルを試したい」という方は、オンライン版をこちらから試すことができます。ローカルよりは性能は劣るのであくまで参考にはなりますが...)
どんな原理で動いているの?
ところで、最近の画像生成AI、やけに文脈(コンテキスト)の理解がよくできるように思えませんか?
そもそも、テキスト指示だけで画像の細かい部分が編集できるなんて、1-2年前はありえませんでした。
先日紹介したNano Banana Proはもちろんのこと、ChatGPT上での画像生成でも雑な指示で意外といい感じの画像が生成できてしまいます。
「なかなか思い通りの画像が出せない」なんて悩んでいた時代から随分と進化したと思いませんか?
実は、こういったことが可能になった背景には、画像生成AIモデルの進化が挙げられます。その中の一つとして、MMDiT(Multi-Modal Diffusion Transformer)と呼ばれる新しい設計が登場してきました。
Nano Banana ProやGPT-Image-1.5(ChatGPT)がMMDiTを採用しているかどうかは、公開情報ベースでは分かりません。両モデルはそれぞれの「最新の画像生成・編集アーキテクチャを使っている」と報じられていますが、MMDiTの採用については、公開されたレポートや公式仕様で明示されていないのが実情です。(残念...)
そもそも、画像生成AIの原理は?
画像生成AIの原理については、Stable Diffusionに遡ります。
詳しい説明は私の過去の記事で解説していますが、「CLIP」と呼ばれる「画像とテキストが互いに類似しているか?」を比較できるモデルがあります。
そのCLIPがテキストを受け取り、「このテキストと類似する画像を作りなさい」と命令しながら作成されるのが、ざっくりとした画像生成AIの原理です。
つまり、画像生成モデルは、最初は適当なノイズだらけの画像を作るのですが、生成の過程で、「あ〜この指示されたプロンプトと同じ画像にしなくちゃいけないんだなぁ」と画像のピクセルを指示内容に近づけていくという特徴を持っています。
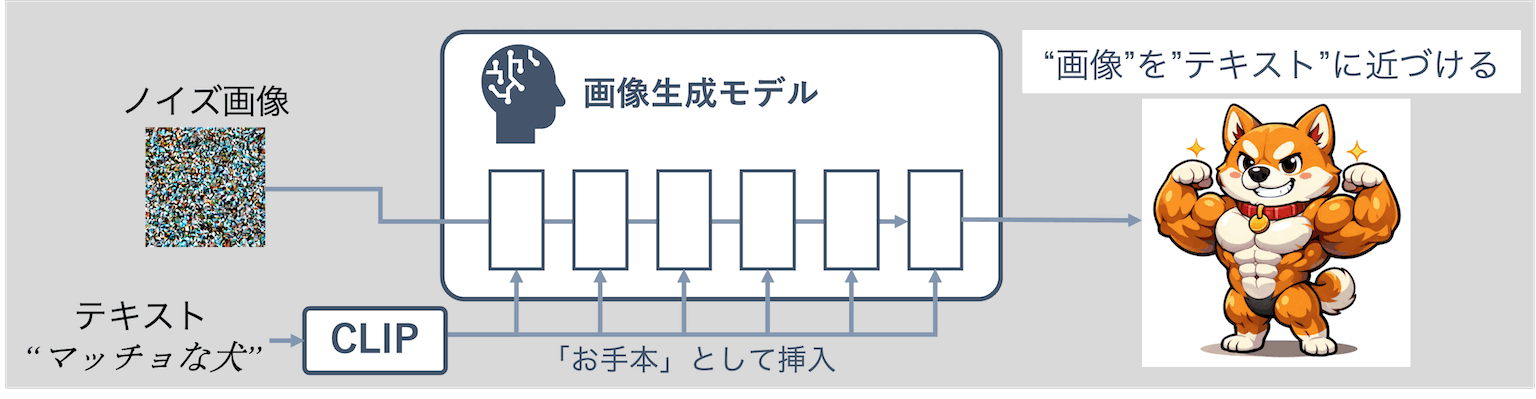
でも、それってよくよく考えてみると、かなり強引だとは思いませんか?
「テキストと同じ表現に画像を合わせろ!」なんて、まるで「俺について来い」と強引に女の子をリードする男子みたいなものです。
例えば、彼(テキスト)が、彼女(画像)に「今日はカフェでデートしよう。レトロで、赤い服で来てね」と伝えたとします。彼女は、それを見て、髪型や服装をそれっぽく寄せていきます。で、彼にチェックをお願いすると、また「レトロで、赤い服で来てね。」と言われます。彼女が何回服装を変えてきても彼のメッセージはずっと一緒。例えば、彼女が赤いタンクトップを着て、古いバーベルを持って行っても「レトロで、赤い服で来てね。」しか返さないのです。
これじゃあ、彼女は困りますよね?
彼女が実際に欲しいのは、「どこが合っていて、どこが合っていないか?」「どこか歩み寄れないのか?」というお互いの思いやりの部分です。
MMDiTの登場
そこで登場したのがMMDiT(Multi-Modal Diffusion Transformer)です。
テキストが画像をリードするだけでなく、テキスト自身も生成モデルの中に入れて、調整していきます。ざっくり言うと、「言い方の表現」を変えたり、どの部分が今のテキストの中で重要なのかを参照したりしつつ、さらに、生成中の画像とも相互に情報を共有することで、情報をアップデートしていきます。
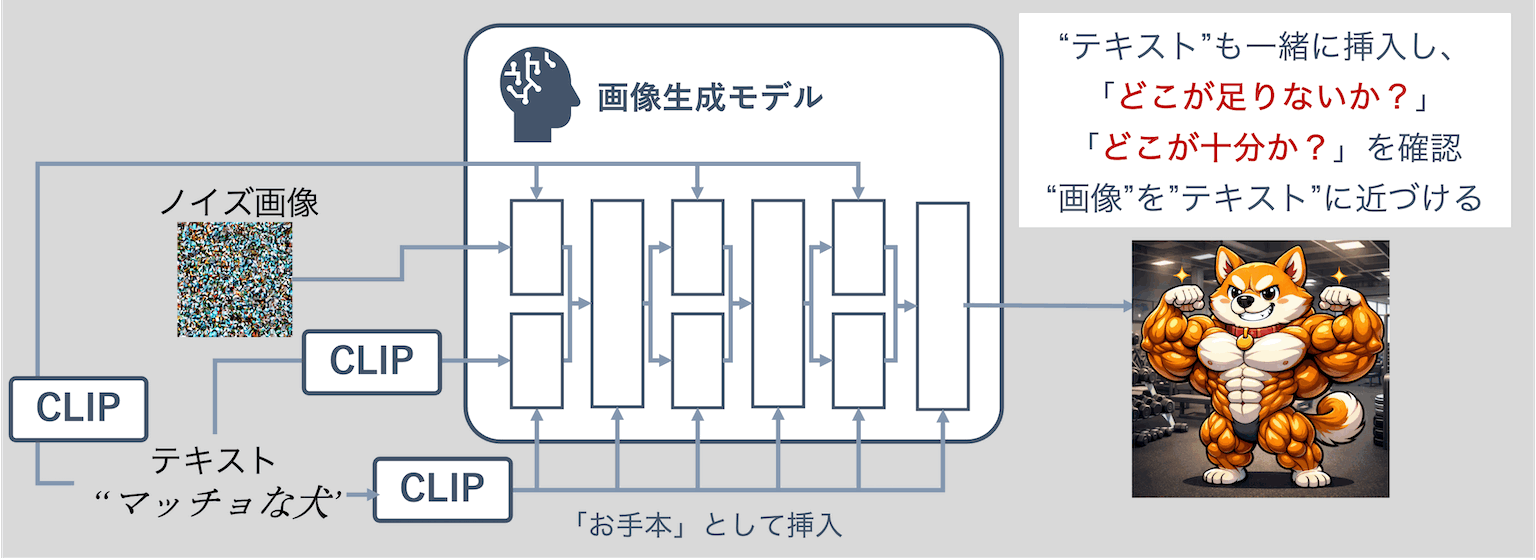
つまり、MMDiTは、彼の希望(テキスト)と、彼女の現状(生成途中の画像)を、同じテーブルに並べて毎ターン一緒に眺める感じです。
彼女は言います。
「その"レトロ"って照明なの?バーベルなの?それともベニスビーチのジムのことを言ってるの?」
「"赤"は口紅?タンクトップ?筋繊維?」
みたいに、彼と彼女の"頭の中の表現"が、相手を見ながら同時に更新されて噛み合っていく。
モデルの中で相互に参照できる回路が強くなっているため、結果として擦り合わせが上手くなる、というわけです。
このMMDiTと呼ばれるモジュールの活用により、文脈(コンテキスト)の理解力は格段に上がりました。
Qwen-Image-Edit-2511も、こうした近年の設計思想の影響を受けたモデルの一つです。
さぁ、やってみよう
さて、前置きが長くなりましたが、早速Qwen-Image-Edit-2511の編集能力を試してみたいと思います。
画像処理の一貫性
まず、旧来のローカルLLMモデルでよくあったのは、画像処理の前後で顔が別人に変化してしまうことですね。Qwen-Image-Edit-2511では、この点も非常によくコントロールできているそうです。
さっそく試してみました。

入力プロンプト (クリックで展開)
Valentine's Day-themed image. One man with a clean yet subtly sensual aura. Do not change the face of the person in the image. He has an extremely muscular, bulky, gorilla-like physique with thick traps, a wide chest, massive shoulders, and powerful arms. Strong "hardcore bodybuilder" vibes. Sharp, intense eyes and a piercing gaze. Place a heart-shaped hair accessory on his head. A small cone-shaped chocolate is neatly fixed on the top of his head, crowned with a golden five-pointed star. The chocolate itself is decorated with colorful light garlands, golden bells, ribbons, and small red, blue, and gold balls, arranged intricately and densely. He holds a snowman plush toy with both hands. Maximize the Valentine's Day atmosphere, with confident, celebratory eyes and expression. Slightly tilt his head in a cute and visually appealing pose. Cuteness and brute strength coexist, creating a strong gap. Slightly tousled hair naturally blends with the chocolate on top of his head. He wears a red tank top that tightly stretches over his thick chest and shoulders. Warm white background with soft studio lighting. Low contrast, low saturation, delicate film grain. Subtle chromatic aberration with gentle light bleed, soft film-like light texture. A warm and soothing atmosphere. A unique perspective with an unconventional composition. Styled like a 70mm film portrait. Outline the figure with green graffiti-style strokes, and fill the surrounding blank areas with various cute Valentine's Day doodles. A hand-drawn collage feel full of childlike wonder and Valentine's spirit. The figure's outline is wrapped in fluorescent red and gold dotted lines and polka dots, filled with cute lettering that says "HAPPY VALENTINE." Medium shot.
【日本語訳】
バレンタインデーをテーマにした画像。清楚でありながら、どこか色気のある雰囲気の男性1人。画像内の人物の顔は変更しない。極めて筋肉質で分厚い僧帽筋、広い胸板、巨大な肩、力強い腕を持つ、ゴリラのように屈強でボリュームのある体格。ハードコアなボディビルダーの雰囲気。鋭く強い眼差し。
頭にはハート形の髪飾りを付ける。小さな円すい形のチョコレートが頭頂にきちんと固定され、頂上には金色の五芒星が乗っている。チョコ本体はカラフルなライトのガーランド、金色の鈴、リボン、赤・青・金の小さなボールで精巧かつ高密度に装飾されている。
両手で雪だるまのぬいぐるみを持つ。バレンタインデーの雰囲気を最大限に高め、自信に満ちた祝祭感のある目つきと表情。軽く首をかしげ、かわいらしく見栄えのするポーズ。かわいさと圧倒的な筋力が共存し、強いギャップを生む。少し乱れた髪が頭頂のチョコレートと自然に融合する。赤いタンクトップを着用し、分厚い胸と肩にぴったりと張り付いている。
暖かい白の背景、スタジオ撮影の柔らかい光。低コントラスト、低彩度、繊細なフィルム粒子。わずかな色収差による光のにじみ、フィルムのように柔らかい光の質感。温かく癒やされる雰囲気。独特の視点と型にはまらない構図。70mmフィルムのポートレート風。緑の落書き風ストロークで人物の輪郭をなぞり、周囲の余白にはさまざまな可愛いバレンタインの落書きを描く。童心とバレンタインの雰囲気に満ちた手描きコラージュ感。人物の輪郭は蛍光の赤と金の点線や水玉で包み、「HAPPY VALENTINE」と可愛い字体で埋める。中景。
この記事を執筆しているのは2月ということで、バレンタインデーを意識した画像を生成してみました。
見事に、入力画像の人物の顔を再現できているように見受けられますね!
「VALENTINE」の文字もきちんと再現できているようですね。さすがMMDiTを使っているだけあります。
別の画像でも試してみましょう。

入力プロンプト (クリックで展開)
A single image divided into two panels. Requirements: Character: Depict the person from the reference image across four separate panels, each with a different pose and facial expression. Do not change the face. He has an extremely muscular, bulky, gorilla-like physique with massive shoulders, thick traps, a wide chest, heavily defined arms, and an overall powerhouse bodybuilder presence. His muscularity should be visually dominant in every panel. left: Tilt the head slightly, wink with one eye, stick out the tongue, and make a "V" sign with one hand. One arm flexed, showing clear muscle definition. Playful and mischievous, but still overwhelmingly muscular. right: Cross both massive arms in front of the chest, muscles tightly packed and clearly defined. Slightly furrow the brows, purse the lips, and show a subtly tsundere-like, slightly aloof expression. His imposing upper body should dominate the frame. Clothing: A tight red tank top stretched over his thick chest and shoulders, clearly emphasizing his muscular build. Background and style: A colorful background with cute cartoon elements. Overall in a 2D anime style. Vivid colors. The atmosphere is sweet and soothing, yet the overwhelming physical strength remains visually striking. Each panel has intricate cartoon-style frame decorations with a childlike sense of fun, creating a strong contrast between adorable presentation and extreme muscularity.
【日本語訳】
分割された1枚の画像。 要件: 人物:参考画像の人物を、2つの画面に分けて、それぞれ異なる動作と表情で描写する。顔は変更しない。極めて筋肉質で、巨大な肩、分厚い僧帽筋、広い胸板、くっきりとした腕の筋肉を持つ、ゴリラのように屈強で圧倒的なボディビルダー体型。すべてのコマで、その筋肉量と存在感が視覚的に支配的であること。 左:頭を少し傾け、片目でウインクし、舌を出し、片手で"V"サインをする。片腕は軽く力ませ、筋肉の輪郭をはっきり見せる。いたずらっぽくふざけた雰囲気だが、圧倒的な筋肉量はそのまま保つ。 右:両腕を胸の前で交差させる。分厚く密度の高い筋肉がはっきりと強調される。眉をわずかにひそめ、口をすぼめ、少しツンとした控えめに不機嫌そうな表情を見せる。上半身の圧倒的な存在感が画面を支配する。 服装:分厚い胸と肩にぴったりと張り付く赤いタンクトップを着用し、筋肉を強調する。 背景とスタイル:かわいいカートゥーン要素が入ったカラフルな背景。全体は二次元アニメ風のスタイル。色は鮮やか。雰囲気は甘くて癒やし系だが、圧倒的な身体的強さが視覚的に際立つ構成。各コマには精巧なカートゥーン風の枠装飾があり、子どもっぽい楽しさを持たせる。かわいらしい演出と極端な筋肉量との強いコントラストを表現する。
画像のドメイン変換(アニメ風)を挟みましたが、大まかな情報は担保できているように見受けられます。
左側の画像では、顔がややリアル寄りの塗りになっていますが、まぁ、合格点としましょう。
続けて、画像の人物の全身を映させてみます。

入力プロンプト (クリックで展開)
A vertical 3:4 image of a scene showing a real person and their corresponding cartoon mural together in one frame. Place the uploaded real-person photo on the left side / foreground of the frame, keeping the original hairstyle and face unchanged. On the wall behind the real person, create a one-to-one corresponding cartoon mural version of them. Use a thick paint texture with large anime-style eyes and softly contoured facial features. Completely replicate details such as hairstyle, facial expression, glasses, and small accessories. Use high color saturation and incorporate graffiti-style brushstroke effects. Add colorful graffiti elements on the wall, such as dumbbells, protein supplements, and geometric patterns. Scatter decorative paint splatter details on the ground. Integrate typographic elements such as "2026" into the mural area, with lettering that matches the graffiti aesthetic. Ensure that the proportions and angles between the real person and the mural connect naturally. Unify the direction of lighting so the scene feels coherent. Keep the overall color style consistent, presenting a vivid, cohesive, and visually harmonious result.
【日本語訳】
縦向き(3:4)の画像を生成し、実在の人物と、その人物に対応するカートゥーン壁画を1つのフレーム内に収めてください。 アップロードされた実在人物の写真をフレーム左側/前景に配置し、元の髪型と顔は変更せずに保持してください。その人物の背後の壁には、本人と一対一で対応するカートゥーン版の壁画を制作してください。 厚みのあるペイント質感を用い、大きなアニメ風の目と、やわらかく輪郭づけられた顔立ちで描いてください。髪型、表情、眼鏡、小さなアクセサリーなどの細部も完全に再現してください。色彩は高彩度とし、グラフィティ風のブラシストローク効果を取り入れてください。 壁にはダンベル、プロテインサプリメント、幾何学模様などのカラフルなグラフィティ要素を加えてください。地面には装飾的なペイントの飛沫を散りばめてください。 「2026」などのタイポグラフィ要素を壁画エリアに組み込み、文字デザインはグラフィティの美的感覚に合うようにしてください。 実在人物と壁画の間で、プロポーションや角度が自然につながるようにしてください。光の方向も統一し、シーン全体に一貫性を持たせてください。全体の色調を統一し、鮮やかでまとまりのある、視覚的に調和した仕上がりにしてください。
「壁画に入力画像と同じ人物をカートゥン調で描きつつ、入力した人物については、そのままの写真のスタイルで再現する」というやや難しめのタスクではありますが、非常に綺麗に再現できているように見受けられます。
自然言語の指示だけでここまでできるのは驚きの一言ですね。
服装や色の変更
また人物の服装の変更や物体の色の変更も、プロンプトだけでできてしまいます。
このように空手道着への変更や、

入力プロンプト (クリックで展開)
Change his outfit into a judo costume.
【日本語訳】
彼の服装を柔道着に変更してください。
車体のボディーカラーの変更もお手のもの!

入力プロンプト (クリックで展開)
change car body color into rainbow
【日本語訳】
車の色を虹色にしてください。
ここ、少し伝わりにくいかもしれませんが、実は、従来のローカルモデルで同じことをするのはかなり大変でした。
画像のどこを変更するかのマスキング処理を人力で行ったり、もしくはControlNetと呼ばれる大規模なモデルを利用したりと、下準備をして、「画像生成モデルにどこを編集するかを明示的に画像内部に埋め込んでおく」必要があったのです。
ところが、今回のQwen-Image-Edit-2511の場合、そのような処理は全くいらず、プロンプトのみできちんと変更が反映されていることがわかります。事前処理で、「服装部分はここ」「車のボディカラーの位置はここ」などと明示的にマスクなどをしなくてもきちんと反映されていることがわかります。
画像の合成
さて、最後に複数枚の画像を合成するタスクも試してみましょう。
2枚の別の人物画像を用意して、2人で一緒にポーズをとっている画像を生成してみたいと思います。

入力プロンプト (クリックで展開)
Two people forming a heart shape together with their hands.
【日本語訳】
2人で手でハートを作っている。
できたぁぁぁ!!!
素晴らしい!完璧ですね。これ、元となる画像があれば、いろんな画像が易々と作れてしまいますね。
年賀状用の写真とか、生成AIだけで済ませることもできてしまえそうです。
以上、Qwen-Image-Edit-2511で、さまざまな画像編集を加えてみました。
淡々と画像を紹介している形にはなってしまいましたが、自分でローカルモデルを触っていて、単純にプロンプトを変更するだけで、いろんな編集が加えられるのは、かなり不思議な感覚がしました。
「いつもなら、パラメータを弄りながら膨大なコードを書いて四苦八苦するのにな...」という少し拍子抜けしたような安心したような感覚がありましたね。
モデルのプロンプト理解力・コンテキスト理解力の向上が、ここまで自分の作業を楽にしてくれているのは驚きの一言です。
まとめ
いかがだったでしょうか?今回は最先端の画像処理モデルであるQwen-Image-Edit-2511の性能を見てきました。
今回検証した Qwen-Image-Edit-2511 は、ローカル環境においても自然言語による高精度な画像編集が実用レベルに到達していることを示しました。従来のローカルモデルではマスキングや補助的な制御が前提となる場面も多くありましたが、本モデルではプロンプトのみで意図した編集が成立すると言う飛躍的な進化を遂げています。
これは、MMDiT系アーキテクチャに代表される「テキストと画像の同時参照設計」による進化が非常に大きいです。コンテキスト理解の向上は、単なる画質向上とは異なる意味で、利便性を向上させてくれていますね。
Nano Banana Proのようなクローズドモデルは、安定性や品質面でトップを走ってはいますが、ローカルモデルもこの水準に近づいているように感じます。
さらに言えば、編集結果の再現性を重視する場合や、特定のプロンプト・設定を固定して安定的に運用したい場合など、ローカルモデルならではの良さも、やはりあります。(表現に関しても、セーフティフィルターのようなものがないので、好きな画像を自由に生成できますしね。)
ちなみに、Qwen-Imageシリーズですが、ちょうどこのブログを執筆している時に新しいモデル"Qwen-Image-2.0"がリリースされたというアナウンスがありました。まだ、現時点ではローカルモデルとしては公開されていないため、詳しく検証はできていないのですが、「Nano Banana ProやGPT-Image-1.5に匹敵する性能」なんだとか...
画像生成AIの発展、これからも楽しみですね。ではまた!





