

どうも、sodaエンジニアの國田です。
突然ですが皆さま、画像生成AIはエンジョイしていますか?
当ブログでもここ暫く画像生成AIのトピックはお休みしていたのですが、先日衝撃的なニュースが入ってきました。2025年11月下旬、新たな画像生成AIモデル「Nano Banana Pro(Gemini 3 Pro Image)」がGoogleから発表されました。
これまでの画像生成AI(例: ChatGPTの4o-Image GenerationやStable Diffusionなど)を上回る高機能な次世代モデルとして注目を集めており、個人的にも非常に興味深いため、共有したいと思います。
以前、ChatGPTの4o Image Generationの機能を紹介した時のことを覚えておいででしょうか?
あの時も衝撃的ではありましたが、今回はそこから更に進化した機能が多く出ていますので順番に紹介していきたいと思います。
画像のクオリティ
既に2-3年前、Stable Diffusion XLが出た頃から画像のクオリティに関しては十分高かった記憶がありますが、今回は更にそのクオリティが上がっています。例えば、「机でPC画面を確認しながらMTGしているエンジニアの男性」の画像を生成させますと、以下のような画像が得られます。

普通に撮影した写真と見分けがつかないくらい、クオリティが高いですよね?
質感や陰影も非常に表現力が高く、初見ではAIが生成したとも気づかない程になっています。
多様なアートスタイル

上記は、先ほど生成した画像を、「アニメ風」「イラスト風」「3D風」「浮世絵風」「絵画風」「砂絵風」「デッサン風」「抽象画風」「ピクセルアート風」に変換させ、生成したものです。
通常、こういった操作を行うと、モデルによってはどうしても表現できないものが出てきたり、なんとか表現できるとしても相当なプロンプトの修正と改良が必要になるのですが、Nano Banana Proでは1回の指示だけで、再現度の高い画像を生成することができました。
テキスト表現の正確性
とにかく、テキストの再現がすごい!実は、今回の記事で私が最も訴えたい点であったりもします。
これまでの画像生成モデルでは文字を画像に再現するのが苦手でした。4o Image Generationでは、何とか読める日本語のレベルまで到達しましたが完全な文字を生成させるには割とギャンブル傾向が強く、文字が抜けていたり崩れていたりといった例がしばしば見られました。
しかしながら、このモデルはほぼ完璧に日本語テキストを再現することが可能になり、例えば、以下のような技術書の画像を生成することが可能です。

Nano Banana Proは短いタイトルから長い段落までクッキリと判読可能な文字を画像に直接埋め込むことが可能になっており、指示追従性と画像化した際の再現性において非常に高い性能をもっていることが伺えます。
一貫したスタイル・キャラクターの再現
Nano Banana Proは同じ人物やキャラクターを複数の画像や場面に渡って統一して描写する能力に優れています。
従来のモデルでは、4コマ漫画のようなものを生成した際、各コマで主人公の顔立ちが微妙に変わったり、服装や装飾品が変化してしまう例がよく見られました。しかしながら、Nano Banana Proでは終始一貫した画像を生成することが可能になっており、以下のそれぞれの漫画での登場人物の外見がコマが変わっても変化していないのがみて取れます。


これは、SNSでも話題になっており、「ついに画像生成AIだけで漫画が描けるのでは?」と言われています。
図表の生成
前述の文字描写の能力や一貫性の能力の高さから、以下のダイアグラムのような図解画像を容易に生成することも可能です。
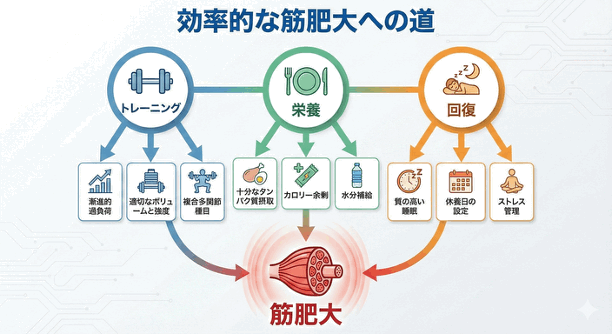
従来のモデルでは、このようなものを作ろうとすると、どこかで破綻が見られたり、画像自体に意味不明なフローが見られたり、論理的にあり得ない構造で矢印が繋がったりといったような問題もあったのですが、そういった問題の発生頻度もかなり抑えられているようです。
検索を活かした知識統合
Googleといえば検索エンジン。実は「名古屋の来週の天気に関する解説画像を作成してください。」というプロンプトだけでも画像を生成することができます。この際、内部的に自動で1週間の天気を検索・取得し、その情報を画像に反映させることができます。
(画像は、2025年12月10日時点で翌週の天気の解説画像を作成させたものです。)

これまで、こういった生成AIは「知識のカットオフ」といった形で最新の事例などは反映することはできなかったのですが、裏側でニュースを収集することにより、自動的に最新知識にアップデートをするといったことも可能になっています。
画像のミックス
複数枚の画像を混ぜることも可能です。まず最初に以下のように3枚の入力画像を用意します。

この状態で「これらの3枚の画像を1枚の集合写真にまとめてください」と指示すると・・・

このようにひとまとめにした画像を生成することも可能です!見事!
以上のように、Nano Banana Proによる画像の生成はリアルさ・美しさと、細部(文字や構図)の正確さなど、これまでのモデルでは難しかった数々のタスクをクリアしています。
ただし万能というわけではなく、小さな顔や極細かなディテールの再現はまだ完璧でない」「長い文章の文法や文化的ニュアンスまでは時に不自然」といった限界もあるようです。
まとめ
いかがでしたでしょうか?
今回は、Googleの新たな画像生成AI「Nano Banana Pro」を検証しました。率直に言って、わずか数年前には想像もできなかったレベルの画像生成能力を実現しており、対話的なインターフェースから誰でも使える点で、従来のモデルより一歩先を行く存在だと感じます。
とはいえ、私が普段推しているStable Diffusionのようなモデルが時代遅れになったとは思いません。他社のモデルもNano Banana Proの登場によって刺激を受け、さらなる進化を遂げていくでしょうし、Stable Diffusionはオープンソースであるがゆえに、対話性や即応性とは別の軸で、カスタマイズ性や保守性、そして機密データを外部に出さずに済むというローカル実行ならではの強みを持っています。商用利用の自由度という点でも、依然として現場での導入余地は大きいと考えています。用途や立ち位置が異なる以上、単純な優劣では測れない部分もあるでしょう。
そうした中で、Nano Banana Proが注目される理由は、あらゆる制約を抱えずに誰でも即座に高品質な出力を得られる"完成された入口"としての設計にあります。
惜しい点を挙げるなら、モデルが非公開であり、どのようなアーキテクチャで構成されているのかが明らかにされていないところでしょう。エンジニア的には、まさにそこが最大の関心事でもあります。
画像生成AI界隈の今後の発展が楽しみですね!
ではまた!





