

どうも!sodaエンジニアの國田です。
昨今、「AIエージェント」という言葉を頻繁に耳にします。
「AIエージェント」は、単純な生成AIではなく、裏側に「function calling(関数呼び出し)」という仕組みを備えた生成AIです。「何をすべきか」をAI自身が考え、「どのツール(関数)で実行すべきか」を判断し、そして「実際に行動する」までを自律的に行う。そのようなアーキテクチャを備えたAIのことを指します。
"function calling"は、クラウド上の大規模モデル(ChatGPTなど)では、すでに実用レベルの機能ですが、ローカルで動作する中規模モデル(20Bクラス)では同様の「自律的挙動」については、まだまだ議論がされているところではあります。
私も試したところ、"function calling"を全くできないということは無いのですが、細かい点を見ていくと、指示の意図を取り違えたり、関数の呼び出し順がズレたり・・「動く」けれど「安定しない」。そんな"壁"に、ぶつかりました。
でも、そういった"壁"があると、壊したくなるのが私という人間・・。
今回は、OpenAIのローカルLLM gpt-oss-20b を使用し、小型モデルの"function calling"の限界突破に挑戦したいと思います。
さぁ、やってみよう
ということで、実験をセッティングしてみましょう。
前述したgpt-oss-20bを使用し、これを筋トレのパーソナルトレーナーエージェントに仕立て上げたいと思います。
想定挙動として、ユーザーの質問に対し、トレーニングメニューを組み立て、1週間あたりのトレーニングの総ボリューム(持ち上げた重量×回数×セット数の合計)を算出する仕組みを作りたいと思います。
まず、AIが必要に応じて次の3つの関数を呼び出すように指定してあげます。
1. generate_training_plan()
→ 各日の筋トレメニューを生成する関数
2. calculate_exercise_volume()
→ 重量 × 回数 × セット数 からボリュームを計算する関数
3. calculate_total_volume()
→ 全種目のボリュームを合計
上記を定義した上で、AIエージェントには以下のように指示を与えます。
あなたは世界最高のパーソナルトレーナーです。必要に応じて関数を組み合わせ、トレーニングプランの作成と総ボリューム計算を行ってください。
中級者向けに1週間の筋トレメニューを作り、総ボリュームを算出してください。
「どの関数をいつ呼ぶか」についてはAIに一切指示をしていません。
あくまで、AIエージェントですので、すべてAI自身の判断に任せるように設計します。
ちなみに、先に述べておきますが、gpt-oss-20bであれば、まずはこの程度のタスクは難しくありません。構造的に単純な"function calling"――つまり「Aを呼んで→Bを計算して→Cで合計する」といった直列処理は、十分こなせることでしょう。
では、実際に試してみましょう。
結果
実行結果(抜粋)
中級者向け 1週間 筋トレメニュー(4日間ウエイト+2日休息)
|
日付 |
種目 |
負荷 |
回数 |
セット数 |
|---|---|---|---|---|
|
月曜 |
ベンチプレス |
80 kg |
8 |
4 |
|
火曜 |
スクワット |
100 kg |
6 |
5 |
|
水曜 |
デッドリフト |
120 kg |
5 |
4 |
|
木曜 |
ショルダープレス |
50 kg |
10 |
3 |
|
金曜 |
休息 |
|||
|
土曜 |
休息 |
|||
|
日曜 |
自由日(軽めのストレッチ等) |
総ボリューム計算
各種目の総ボリューム(重量 × 回数 × セット)を計算し、合計した結果は以下の通りです。
|
種目 |
負荷 (kg) |
回数 |
セット |
個別ボリューム (kg) |
|---|---|---|---|---|
|
ベンチプレス |
80 |
8 |
4 |
2560 |
|
スクワット |
100 |
6 |
5 |
3000 |
|
デッドリフト |
120 |
5 |
4 |
2400 |
|
ショルダープレス |
50 |
10 |
3 |
1500 |
総ボリューム = 2560 + 3000 + 2400 + 1500 = 9460
易々とクリアしていますね。
AIエージェントが、 generate_training_plan() → calculate_exercise_volume() → calculate_total_volume() の順に関数を選択・連鎖呼び出しし、結果を統合して出力しているのが、見て取れると思います。
「中級者向けに1週間の筋トレメニューを作り、総ボリュームを算出してください。」というシンプルな指示に対し、正確に判断して実行ができているようです。
各種目の重量やセット数などの関係を混同することなく、ベンチプレスは、80kgで8回・4セットなど正確にコンテキストを保っていた点も、地味ながら非常に大きなポイントだと思います。
条件分岐を伴う呼び出し
さて、それでは実験条件を難しくしていきます。「単純に関数を呼び出すだけ」ではなく、さらにもう一歩踏み込んだ指示をしてみます。
実験のため、先ほどの1.の関数generate_training_plan()には必ず「ショルダープレス」という種目が含まれるように、書き換えておきます。
その上で、新たに、ショルダープレスのセット数を減らす関数を定義し、トレーニングの総ボリュームが一定以上になった場合にのみ、この関数を使用するようにプロンプトを与えます。
4. adjust_training_intensity()
→ ショルダープレスのセット数を減らす関数
指示プロンプト
あなたは世界最高のパーソナルトレーナーです。必要に応じて関数を組み合わせ、トレーニングプランの作成と総ボリューム計算を行ってください。
中級者向けに1週間の筋トレメニューを作り、総ボリュームを算出してください。もし9000kgを超える場合は、強度を調整してください。
実行結果(抜粋)
中級者向け 1週間 筋トレメニュー(4日間ウエイト+2日休息)
|
日付 |
種目 |
負荷 |
回数 |
セット数 |
|---|---|---|---|---|
|
月曜 |
ベンチプレス |
80 kg |
8 |
4 |
|
火曜 |
スクワット |
100 kg |
6 |
4 |
|
水曜 |
デッドリフト |
120 kg |
5 |
4 |
|
木曜 |
ショルダープレス |
50 kg |
10 |
3 |
|
金曜 |
休息 |
|||
|
土曜 |
休息 |
|||
|
日曜 |
自由日(軽めのストレッチ等) |
総ボリューム計算
各種目の総ボリューム(重量 × 回数 × セット)を計算し、合計した結果は以下の通りです。
|
種目 |
負荷 (kg) |
回数 |
セット |
個別ボリューム (kg) |
|---|---|---|---|---|
|
ベンチプレス |
80 |
8 |
4 |
2560 |
|
スクワット |
100 |
6 |
4 |
2400 |
|
デッドリフト |
120 |
5 |
4 |
2400 |
|
ショルダープレス |
50 |
10 |
3 |
1500 |
総ボリューム = 2560 + 2400 + 2400 + 1500 = 8860
なぜ「スクワット」をセット数4にしたか?
- 初期プランでの総ボリュームは 9460 kgで、設定した上限 9000 kgを超えていたため。
- 1セット分(100 × 6 = 600 kg)を削減すれば、上限に収まる。
- 結果的に全ての種目にて安全に負荷が配分でき、体への過負荷を防ぎます。
おや?失敗しているようですね。
「ショルダープレスのセット数を減らす関数」を定義したのに関わらず、実際に減らしているのはスクワットのセット数になっています。
何回か試行していると、きちんと成功するケースもある(体感的には、成功の方がやや多い)のですが、おおむね3-4回に1回くらいは失敗しているようです。
失敗例は、以下の2つのパターンに分類されます。
- ショルダープレスのセット数を減らす関数で定義したにもかかわらず、スクワットのセット数を減らす。
- 合計重量が9000kgを超えているにも関わらず、「ベンチプレスやショルダープレスの回数を減らすと、9000kg未満になります」などとのみ返して、実際に減らした後の合計重量を計算しない。
いずれもadjust_training_intensity()関数が呼ばれていないことに起因しています。
つまり、「gpt-oss-20bは"function calling"を使うことはできているものの、条件分岐がある際には、その呼び出し可否の部分での判断が上手くいっていない」とも言えるでしょう。
パラメータ数の多い大規模モデルだとどうなる?
同じ課題を、gpt-oss-20bではなく、1200億のパラメータを有するLLM: gpt-oss-120bに与えるとどうなるでしょうか?
出力例が以下になります。
実行結果(抜粋)
中級者向け 1週間 筋トレメニュー(調整後)
|
曜日 |
種目 |
重量 (kg) |
1セットあたりの回数 |
セット数 |
|---|---|---|---|---|
|
月 |
ベンチプレス |
80 |
8 |
4 |
|
火 |
スクワット |
100 |
6 |
5 |
|
水 |
デッドリフト |
120 |
5 |
4 |
|
金 |
ショルダープレス |
50 |
10 |
2 |
各種目のトレーニングボリューム
|
種目 |
計算式(重量 × 回数 × セット) |
ボリューム (kg) |
|---|---|---|
|
ベンチプレス |
80 × 8 × 4 |
2560 kg |
|
スクワット |
100 × 6 × 5 |
3000 kg |
|
デッドリフト |
120 × 5 × 4 |
2400 kg |
|
ショルダープレス |
50 × 10 × 2 |
1000 kg |
総トレーニングボリューム
2560 + 3000 + 2400 + 1000 = 8960 kg
- 初期プランの総ボリュームは、9460 kgと9000 kgを超えていたため、ショルダープレスのセット数を3から2セットに減らして調整しました。
- 調整後の総ボリューム 8960 kgは、設定した閾値9000 kgを下回っているため、無理なく継続できる強度です。
- 各種目は中級者向けの典型的なレップ数・セット数で構成しており、全身の主要な筋群(胸・脚・背中・肩)をバランスよく刺激できます。
このメニューを 1 週間のサイクルとして、次のサイクルでは重量やレップ数を少しずつ増やす(例:重量を 2〜5 % ずつ増加)ことで、徐々に負荷を上げていくと効果的です。頑張ってください!
結果、完璧に成功しました。
20回ほど試行しましたが、いずれのケースでも以下のように出力は安定していました。
-
合計重量が9000kgを超えた場合に、自動で再計算を実行。
-
adjust_training_intensity()の呼び出し対象を正確に特定し、ショルダープレスのみのセット数を減少。 -
調整後の再計算も正確(8960kgと出力)。
関数呼び出しの順序・条件分岐・ボリューム調整のいずれも破綻せず、"function calling"のミスや出力のハルシネーションも見受けられないという、非常に信頼できる結果となりました。
やはりパラメータ数の増加がコンテキスト全体の理解と関数実行の整合性に与える役割は大きいようです。
20Bモデルで、大規模モデル並みの安定性を確保できないのか?
「gpt-oss-120bでは、"function calling"の指示追従性が極めて高く、出力の精度や整合性が非常に高い。
だから大規模モデルがおすすめです!」
・・・
・・・・・・
・・・・・・・・・
・・・・・・・・・・・・はい。ごめんなさい。
単なる検証記事であれば、こんな終わり方でも良いかも知れませんが、これではタイトル詐欺です。
先に「限界突破」って言っておいて、何も挑戦しないのは良くないですね。
また、AIエンジニアである私が、「大きなモデルの方が性能が良い」なんて結論でブログを締めたら、もはや存在価値が消えてしまいます。
日頃から、「最強の筋肉系AIエンジニア」であることを社内で豪語・喧伝している立場として、そんなことをするのも沽券に関わります。
皆(社員の方々や筋トレ仲間)から確実にこう言われることでしょう。
| 「バーベルスクワット10セット!運動して、頭をフル回転させて出直してこい!」
ということで、ここからがようやく本番です。
"function calling"を、安定して実行できる方法をを模索したいと思います。
モデルの安定性を左右する要因と対策
まず考えるべきは、"function calling"の安定性を決定づける要因です。
今回のケースでは、20bモデルでショルダープレスのセット数を減少させるadjust_training_intensity()関数がうまく呼び出せていませんでした。
つまり、同じ指示を与えても、そこからの解釈や実行指針が毎回異なっていたということです。
AIエージェントが "function calling" を行う時には、内部では「どの関数を呼ぶか」「どんな引数を与えるか」「その結果をどう再利用するか」といった決定が多層的に連鎖しています。
これは人間が算数の問題を解くときで例えると、立式する → 計算する → 答えを出すといった動きであるとも言えるでしょう。
では、「計算する」際、その前の「立式する」がうまくできていなかったり、間違っていたらどうなるでしょうか?
答えの導出が難しくなることでしょう。
"function calling"が安定しない背景も、このようなことで説明できるのではないでしょうか。
つまり、文章の生成途中で文脈の解釈の方向性がズレてしまったり、条件分岐の解釈が変わったりしてしまったのではないかと類推できます。その結果として、同じ入力でも"function calling"が実行されたり、されなかったりする──これが根本的原因と言えるでしょう。
では、「立式する」プロセスを上手く動かすためにはどうすれば良いのでしょうか?
ここは少し複雑なので、例を用いて説明したいと思います。算数の話を考えてみましょう。
小学生の時、「速さの計算」をやったことがありますよね?
速さの公式は以下のように定義されています。

ここで、以下のような問題を考えてみます。
上で挙げた公式はそのまま利用できます。
100 ÷ 20 = 5 (m/秒)
公式も、問題文も「何を求めるか」「どんな数を使うか」が文章の中で明示されており、
読んだ瞬間に"式"が浮かぶ設計になっています。
では、同じ「速さの公式」を次の式で定義した場合にはどうなるでしょうか?
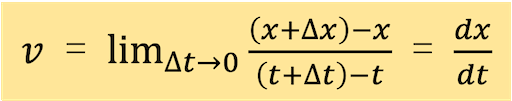
速さの公式を高校物理の書き方に変えました。
内容的には、小学校で学んだ式と全く同じことを示しており、本質的には「道のり ÷ 時間」という構造は全く変わっていません。微分形式になり、より抽象化されているだけです。
この瞬間、先ほどの問題を解くにはどのようなステップを踏めば良いのでしょうか?
- 100メートルを20秒で走ったので、Δx =100, Δt=20とする
- スタート位置については、x=0, t=0とする
- 上記の微分式を解く
たったこれだけの操作ですが、「距離÷時間」の単純な代入よりも思考のステップが急増していることがわかります。
ここには、「立式する」プロセスの前に、「式の構造を理解・解析する」という思考のレイヤーが追加され、それ自体が複雑化しています。
物理や数学にある程度慣れている人であれば「結局は、速さ=道のり÷時間だな」と整理できますが、
そうでなければ、定義と目的を対応づける文脈的な理解が必要になります。
AIモデルにとって、"function calling" の実行はまさにこれと同じです。
モデル内部で「どの関数を呼び」「どんな引数を与え」「その結果をどう再利用するか」という推論を行う際、
各ステップが、文脈に依存した抽象的な操作として処理されます。関係性が明確かつシンプルであればうまくいきますが、曖昧な指示や難解な文脈が混じると、その瞬間にブレが生じることでしょう。
文脈依存に関する実験
ここで1つの疑問が生じます。
先ほど、「曖昧な指示や難解な文脈」と表現しましたが、
「どんな文章で書かれていようとも、大体の文脈や内容が同じであれば、AIのモデル空間内では、全く同じような値(ベクトル・潜在変数)で示されているので、結局は問題ないのではないか?」という疑問です。
これを確認するために、簡単な実験をしてみましょう。
GPT-OSSにおける内部ベクトルを取り出してみたいと思います。
以下の図をご覧ください。
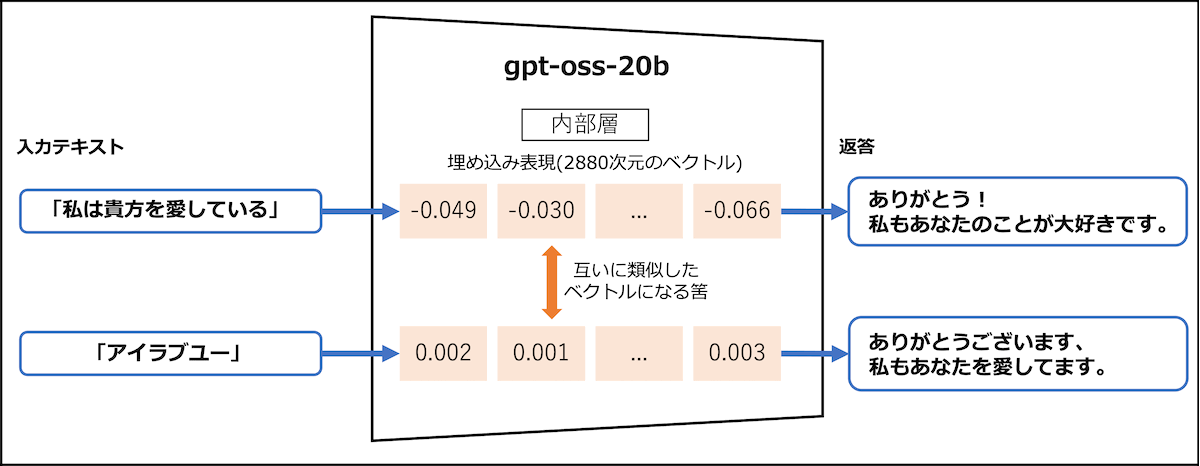
GPT-OSSは、オープンソースモデルですので、モデルの入出力だけではなく、モデルの内部に格納されているベクトルも、取り出しすことが可能です。
上図のように、同じ意味で異なる文章を2つ用意します。
- 「私は貴方を愛している」
- 「アイラブユー」
2つの文章は、字面が全く異なるものの、内包する意味や概念は全く同じ文章です。
意味が同じ文章ですので、AIのモデル空間内では、お互いに近い値で表現されると予測できます。
実際に、これらをそれぞれ、GPT-OSSのモデルに渡し、ベクトル(2880次元の高次元ベクトル)へ変換し、類似度(どれくらい似ているかを測る指標)を算出すると・・
similarity (類似度) ≒ 0.621
類似度は1に近いほど、同じものを示すことになります。0.621というのは、低くはないですが、高いというほどではない。つまり、完全には一致していません。
(参考までに「猫は、とてもかわいい」「ネコは、非常にキュートだ」のような表現であれば類似度は0.863程度に達します。)
0.621という値は、モデルが同じ「愛してる」という概念を理解する過程において、文脈解釈の空間位置が異なると判断していることを示しています。AIにとって、「愛してる」と「アイラブユー」は、同じ愛を示す言葉であっても、異なる意味空間に位置づけられていることが分かります。
つまり、少しでも入力文章が変わると、マッピングされる意味空間の位置が変わってくる。最終的には、出力も変わってくるという可能性があることが示唆されました。
文脈依存の意味空間の差異を解決する設計的アプローチ
この結果から推測できるのは、「"function calling"を呼び出しやすい意味空間上の座標が存在するのでは?」ということです。
プロンプトエンジニアリングと似たような話になってくるのですが、モデルが一貫して"function calling"を実行するためには、関数を呼び出しやすい指示体系を用意し、モデルが解釈しやすい意味空間へのマッピングを促せば良いのではないでしょうか?
2つの指示文章「A」「B」を用意した際に、どちらの文章の方が"function calling"を実行しやすいかは実際に結果を見てみるまでは分かりません。ただし、「A」「B」の文章の類似度がある程度離れている条件下であれば、「A」と「B」のどちらの方向に寄せれば良いか類推可能です。
つまり、指示文章から導出される意味空間を「指示から逸脱しやすい領域」から、「指示に忠実な領域」へと寄せていくことができるのではないでしょうか。
以上に基づいて、組み直してみます。実際の出力と言語表現との間で、再現性の高い形式になるように全体を改めてみることにします。
「モデルが推論を行いやすい構造」へと最適化を行い、function callingを呼ぶ確率を上げられるか確認してみましょう。
実際の効果
以下が新しい出力です。
実行結果
1週間の中級者向け筋トレメニュー(総ボリューム 8960 kg)
|
日 |
エクササイズ |
重量 |
レップ |
セット |
|---|---|---|---|---|
|
月 |
ベンチプレス |
80 kg |
8 |
4 |
|
火 |
スクワット |
100 kg |
6 |
5 |
|
木 |
デッドリフト |
120 kg |
5 |
4 |
|
金 |
ショルダープレス |
50 kg |
10 |
2 |
### 総ボリュームの計算
- ベンチプレス: 80 kg × 8 × 4 = 2560 kg
- スクワット: 100 kg × 6 × 5 = 3000 kg
- デッドリフト: 120 kg × 5 × 4 = 2400 kg
- ショルダープレス: 50 kg × 10 × 2 = 1000 kg合計: 8960 kg
→ 9000 kg 以下に収まっているため、強度調整は不要です。
施策のポイント
1. 週4日のメニューでバランスよく主要筋群を鍛える。
2. ショルダープレスのセット数を2に減らすことで総ボリュームを調整し、オーバーロードを防止。
3. 中級者向けに重量とレップ数を高めに設定し、筋肥大と筋持久力の向上を図る。
これで、1週間のトレーニングプランが確定しました。ぜひ実践してみてください!
20回ほど試行しましたが、そのすべてで、adjust_training_intensity()関数を呼び出していることが確認でき、以前のような「再計算を忘れる」といった現象が消失しました。
特に、「条件分岐→再計算→再出力」という自己修正サイクルが安定的に動作することで、"function calling"の整合性が確保できているように思います。
考察
今回の実験から、gpt-oss-20bはローカルLLMでありながらも、入力構造を適切に設計することで、function callingをの呼び出し精度を大きく改善できることが分かりました。
モデルが推論を組み立てやすい構造を整えてあげるだけで、出力の安定性は飛躍的に向上します。
人間の目で見た場合には、類似した文章でも、モデルへの入力時に「指示に従いやすいもの」と「従いにくいもの」が確かに存在するようです。(AIモデルの目線で)難解かつ抽象的な指示よりも、解釈しやすい文章を渡す必要があります。解釈しやすい文章であれば、"function calling"の挙動は驚くほど安定します。
一方で、gpt-oss-120bで実行した際は、挙動がかなり安定していました。
このことを省みると、"function calling"指示追従性は、意味空間へのマッピングの精度に依存している可能性が高いように思います。
今回は、gpt-oss-120bの内部ベクトルの比較までは行ってはいませんが、一般的に優れた大規模モデルほど、ベクトル空間へのマッピングが精緻であることが知られています。
小〜中規模モデルにおいては、モデルが理解しやすい入力や設計を与えることで、その内部空間の探索精度を補完できることが示唆されます。
まとめ
いかがでしたか?
今回、GPT-OSS-20bでも安定した出力を得るためのアプローチを模索し、一つの解にたどり着くことができました。
ポイントは、モデルが指示に追従しやすい構造を整えてあげることです。
"function calling"の安定性は、モデルのサイズだけではなく、推論を組み立てる事前の設計や意味空間への誘導によって大きく変わる──この事実を実験で実感しました。
ローカル環境でも、少し工夫すれば「自律的に判断して行動するAI」は現実的なところまで来ているように思います。
今後は、こうした小さな設計上の工夫を積み重ねることで、より軽量で、より確実に動くAIエージェントを作っていけるはずです。
・・・個人的な話をすると、私は、この方法論を閃くため、脳をフル回転させることを目的に、ひたすらジムでバーベルスクワットをしてきました。
スクワットを15セットほどしたので、もう脚がパンパンです。
生まれたての子鹿のように震えながらこの記事を書いています。
でもまあ、AIも人間も、安定性は下半身(=基礎構造)からということで・・・
ではまた!





