

はじめに
こんにちは、マーケティングアナリストの倉田です。
今回のテーマは「商圏ポテンシャル」の評価をシンプルにする事!
前編では、AIエリアスコアリングのスコアを活用して、出店戦略におけるアクションプランの考察例をご紹介しました。
前編の記事はこちら
今回はその続きとして、
- スコアの活用例(前編)
- スコアの算出方法と、その実践的な価値(本記事)
- AIによるスコアの信頼性について(後編)
- 未知の商圏でのスコアリング活用例(後編)
について、詳しく解説していきます。「そもそも、あのスコアはどうやって作られているの?」という疑問にお答えします。
どうやってスコアリングしているのか?
スコアリングの手法は2種類あり、精度によって使い分けております。ここからはシンプルで説明がしやすく、柔軟に調整できる手法についてお伝えします。
■AIによる予測の説明
まずAIは、目的変数(予測したい項目: 今回なら店舗の有無)と、それに影響を与えそうな説明変数(様々な要因)の関係性を、準備したデータから学習し、独自の「予測モデル(≒予測式)」を構築します。
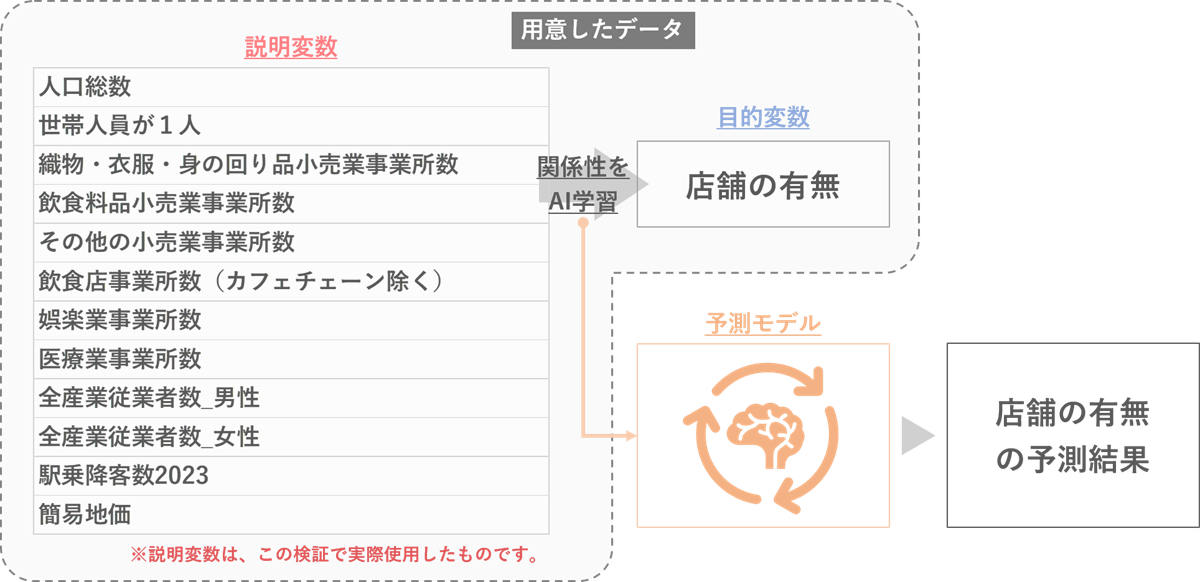
この予測モデルに、分析したいエリアの説明変数(様々な要因)を当てはめることで、予測確率を算出するのが基本的な仕組みです。
※説明変数は様々な組み合わせをテストし、上記12項目に落ち着きました。
■重要度の活用
AIは予測モデルを作る過程において重要度というものを算出してくれます。これは「店舗の有無を判断する上で、どの説明変数が、どれだけ重要か」を数値で表します。その各説明変数が持つ「重要度」を「重み」として使い、エリアのポテンシャルを総合的に点数化します。これが、エリアスコアリングの『スコア』の正体です。
■重要度表
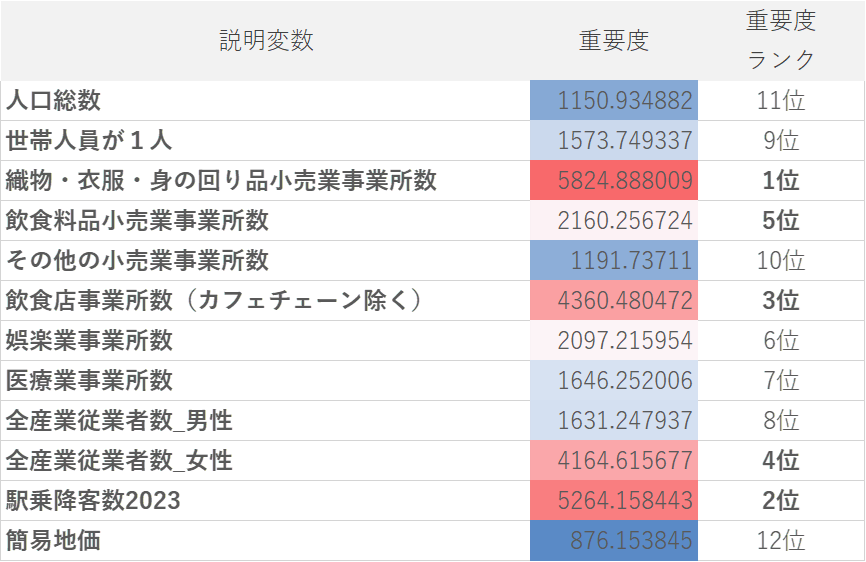
※「重要度」はあくまで店舗の有無を予測するうえで重要だった度合を数値で表したものです。例えば駅乗降客数が多ければ、店舗がアリになるといった因果関係を表している訳ではありません。また、説明変数の組み合わせが変わったり、設定する数値を変えると、重要度はガラっと変わります。
■予測・スコアリング結果(一部抜粋)
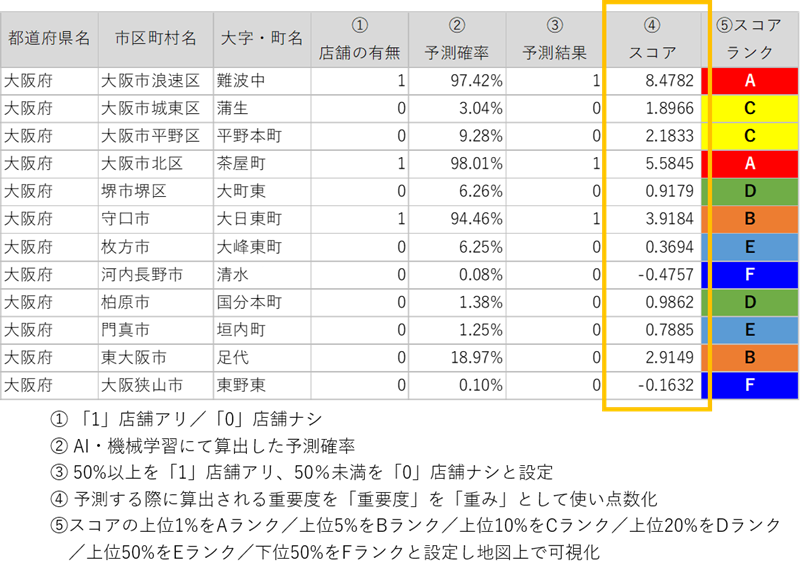
このように説明変数12項目の指標を1つの指標へとすることで評価がシンプルになります。
スコアの先にあるもの:重要度から仮説を立てる
このパートは、テーマから少し外れた話、言わば余談になります。
今回の検証で特に重要度が高かったのは、以下の4つの変数でした。
-
『織物・衣服・身の回り品小売業事業所数』(アパレル)
-
『駅乗降客数2023』
-
『(カフェチェーンを除く)飲食店事業所数』
-
『全産業従業者数_女性』
 上位3つは、多くの方が「なるほど」と感じるのではないでしょうか。アパレル店や飲食店が集まり、駅の乗降客が多いエリアは、まさにこのカフェチェーンが出店するような、活気のある中心地や繁華街、商業施設などのイメージと重なります。
上位3つは、多くの方が「なるほど」と感じるのではないでしょうか。アパレル店や飲食店が集まり、駅の乗降客が多いエリアは、まさにこのカフェチェーンが出店するような、活気のある中心地や繁華街、商業施設などのイメージと重なります。
ここで特に興味深いのが、4位の『働く女性の数』です。
これは単に「客層に働く女性が多そう」という短絡的なイメージではなく、より深い示唆を与えてくれています。『全産業従業者数_女性』という変数は、このカフェチェーンが出店するのに適した複数の好条件が揃ったエリアを特定する、非常に優秀な「代理」の指標として機能している可能性があります。
具体的には、以下のような側面を同時に示唆していると仮説が立てられます。
-
商業エリアの活気: アパレルや飲食店といった業種は女性の従業員比率が高いため、「働く女性が多い」ことは、そのエリアが華やかな商業地であるかもしれません。
-
オフィス街の性質: 同時に、平日昼間の人口が多いオフィス街としての性質が垣間見えます。これにより、出勤前や休憩時間の安定したコーヒー需要が見込めそうです。
-
ライフスタイルの親和性: さらに、都市部で働く女性のライフスタイルや消費行動が、このカフェチェーンの提供する「自分へのご褒美」や「洗練されたサードプレイス」といった価値観と特に共鳴しやすい、という側面もあるかもしれません。
このようにAIは、分かりやすい相関だけでなく、一見すると間接的に思えるデータから、ビジネスの成功に繋がるエリアの「隠れた本質」を浮かび上がらせてくれるのです。
※あくまで重要度起点からの仮説です。これらを証明するには別途検証が必要です。
なぜ「予測」ではなく「スコアリング」なのか?
本題に戻ります。以下のような疑問を持たれる方もいらっしゃると思います。
「AIで店舗の有無を予測しているのだから、そのまま予測結果を使えば良いのでは?」
なぜ使わないのか?結論はシンプルです。
-
一つは、予測精度が上がらないから。
-
そしてもう一つ、スコアで見るとマーケティング的には十分使えるから。
ここでは、この2つの理由をもう少し掘り下げて説明します。
1. なぜ予測精度は上がらないのか
まず前提として、このタスクは「店舗アリ/ナシ」という二値分類問題と言われるものです。実際に大字や町丁目といった粒度での「店舗アリ」のエリアはごく一部(全体の数%程度)です。こうした「不均衡データ」では、分類精度を高くするのはそもそも難しい構造になっています。
また、いきなり予測結果が出る訳では無く、予測確率という0~1の間の数値が算出され、一般的に0.5以上なら「1: 店舗アリ」とします。つまり予測確率が0.51、0.49とほぼ差が無くても画一的に「店舗アリ/ナシ」とするため精度は上がりづらくなります。
加えて、モデルで使えるデータにも限界があります。今回利用しているのは国勢調査や経済センサス、地価、駅乗降客数といった公的統計データが中心です。実際の店舗の有無の要因の一部には、
-
競合ブランドとの直接的な駆け引き
-
商業施設や再開発プロジェクトの有無
-
有料店舗物件の空き状況
-
ブランド戦略上の意思決定(エリアのイメージとの乖離など)
といった公的統計データでは把握できない要因が多く存在します。
ただしエリアスコアリングの目的は店舗の有無を予測する事ではなく、商圏のポテンシャルをシンプルに測ることですので、予測結果に一喜一憂しません。
2. なぜスコアで見ると十分使えるのか
「店舗アリ/ナシ」をピタリと当てにいくと精度は低く見えますが、予測確率やスコアリングを降順で並べ替えランキングを付与すると一気に価値が出ます。
今回の大阪府でのカフェチェーンの検証で使用した以下の③テストデータを、ランダムに10等分した場合とスコア降順で10等分した場合を比較しました。
■データの割り振り
【①全体】大阪府の大字数: 3,518/大阪府の店舗のある大字数108
【②学習・検証データ(①の70%)】大字数: 2,462/店舗の有る大字数: 76
【③学習に使っていないテストデータ(①の30%)】大字数: 1,056/店舗の有る大字数: 32
■ゲインチャート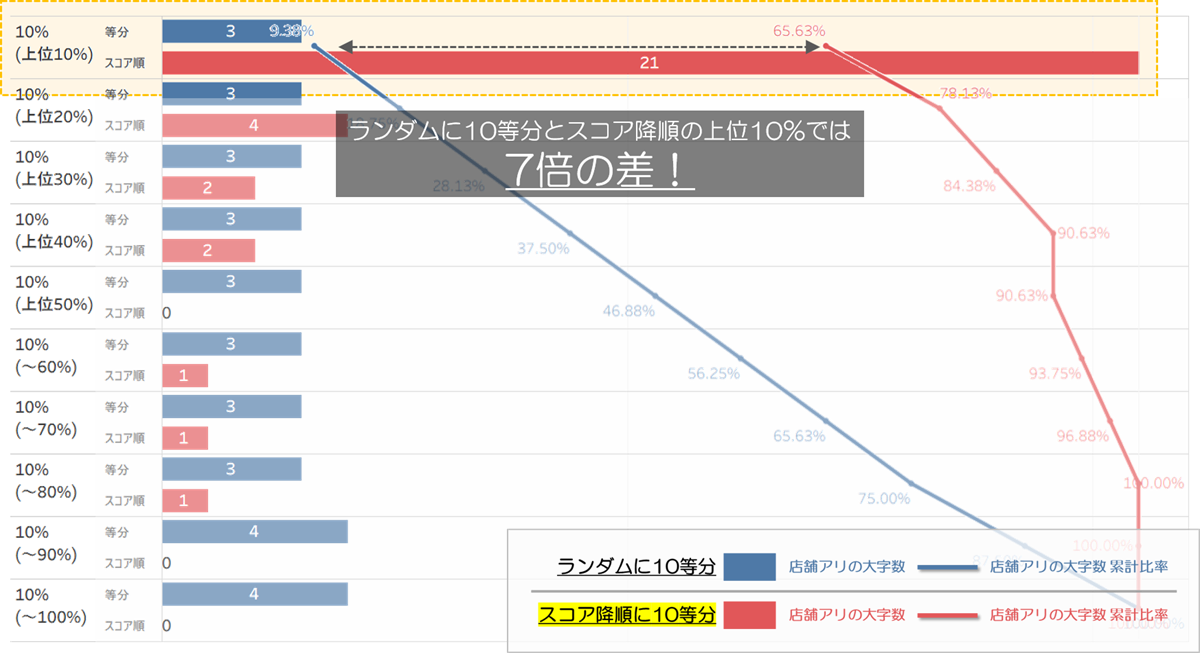
ランダムに等分の場合、10等分したうちの一つには店舗のある大字数は理屈上3~4(32÷10)しか含まないのに、「スコア上位10%のエリア」だけを見れば店舗のある大字数は21が含まれ、全体の2/3近くを捕捉できています。これはランダムに選ぶ場合に比べ7倍効率的です。
つまり、「当てる」ことは難しくても商圏のポテンシャルの高いエリアを「効率よく見つける」ことは十分にできます。この視点に立つと、マーケティングにおいては予測分類精度よりもスコア降順のランキングが重要だとわかります。
まとめ:AIの「予測」を、ビジネスの「評価」に変える
今回は、スコアの算出方法と、「当てる」ことよりも「効率よく見つける」ことを重視する、エリアスコアリングの考え方について解説しました。
AIが学習した「重要度」という思考プロセスを基に、ビジネスの意図に合わせて調整できる「スコア」という物差しを持つことで、初めて私たちはエリアのポテンシャルを客観的に、そしてシンプルに評価できるのです。
さて、こうして作り上げられたスコアですが、その信頼性はどれほどのものなのでしょうか?
次回はシリーズの最終回として、「AIによるスコアの信頼性」や「未知のエリアでの活用例」について、さらに深掘りしていきます。どうぞご期待ください!
エリアスコアリングのサービス概要は下記URLをご参照ください。





