

はじめに
こんにちは!マーケティングアナリストの倉田です。
今回も生成AI(LLM)をテーマにします。
前回の検証 では、都道府県レベルの低精度データに対して、生成AIによる修正は約67%が正解という結果でした。
今回はその第2弾。実務で最も発生しやすく、かつ厄介な 『不完全な住所』をどこまで改善できるか に挑みます。具体的には、「大字」や「字丁目」、さらには「街区」レベルで止まってしまった住所を、正確な「番地・枝番」まで引き上げる検証です。
先に結果だけお伝えすると、今回は 修正の正答率を約83% まで高められました。
...が、今回の検証プロセスで、私は 生成AIの進化に対する「驚き」と、正直に言って「少しの虚無感(笑)」 を味わうことになりました。今日はそのリアルな舞台裏も並行してお届けします。
モチベーション
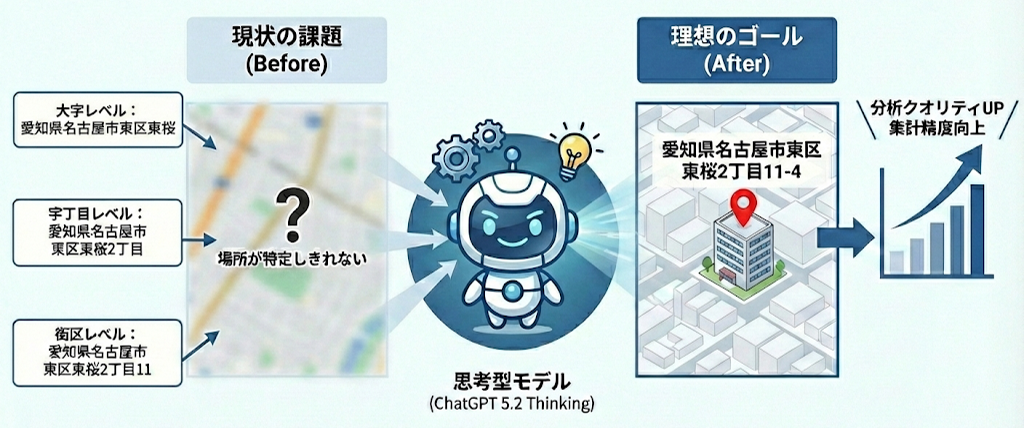
前回と同様にジオコーダーにかけても「場所が特定しきれない」とされる以下のようなデータを対象にしました。
| ●大字レベル | : | 愛知県名古屋市東区東桜 |
| ●字丁目レベル | : | 愛知県名古屋市東区東桜2丁目 |
| ●街区レベル | : | 愛知県名古屋市東区東桜2丁目11 |
理想のゴールは、これらをすべて共通の正解である 愛知県名古屋市東区東桜2丁目11-4 へ半自動で導き、集計の精度を上げ、分析のクオリティアップにつなげることです。
※ChatGPTチームプランの思考型モデル(ChatGPT 5.2 Thinking / じっくり考えてから回答を出すタイプ)を、検証の公平性を考慮し一時チャットモードで使用しました。
※また、この記事の内容は2026年1月末時点の検証結果によるものです。
1週間かけた「渾身のガッツリプロンプト」
私はこの検証のために1週間強の時間を費やし、ノウハウを注ぎ込んだプロンプトを作り上げました。
前回とは違うアプローチとしては、「都道府県」「市区町村」「大字(町名)」「字・丁目」「それ以降(街区/住居番号/番地/枝番/号)」「建物名」と住所を分解し、
- 都道府県 + 市区町村 + 大字(町) + 番地(+枝番)
- 都道府県 + 市区町村 + 大字(町) + 小字 + 番地(+枝番)
- 都道府県 + 市区町村 + 大字(町) + 丁目 + 街区 + 住居番号(+枝番)
- 都道府県 + 市区町村 + 番地(+枝番)
と4つの住所構造を判定させることで、IF文(フローチャート)のような条件分岐がしやすいよう、住所改善のパターン化を試みました。
衝撃の検証結果:1週間の作り込み vs 実質1行の指示
ところが、検証も最終盤に差し掛かったところで「最新の思考型モデルには、細かな手順指示は不要である」という説を目にしました。半信半疑で、私が1週間かけた「ガッツリプロンプト」と、実質1行の目的だけを伝えた「シンプルプロンプト」を比較してみたのです。(実際のシンプルプロンプトは後述します)
精度は、ほぼ変わりませんでした(苦笑)。
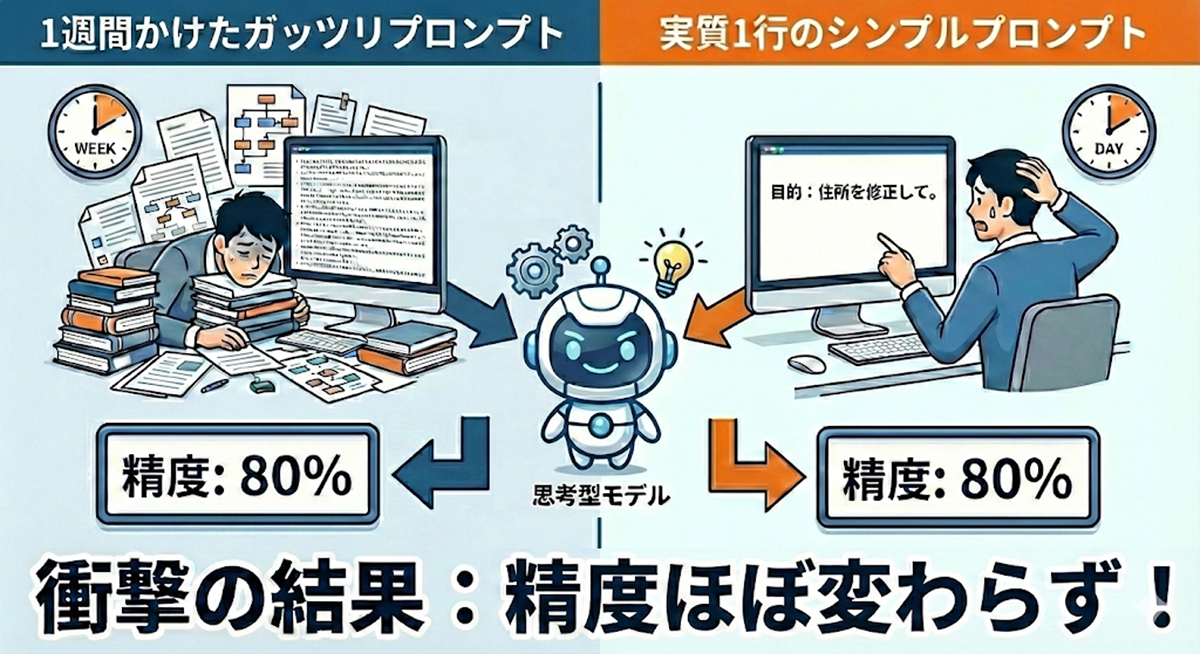
ただし、 どちらも12レコード中10レコードが正解(正解率 約83%)という結果なので、十分に実務で使えるレベル と言っていいのではないでしょうか。
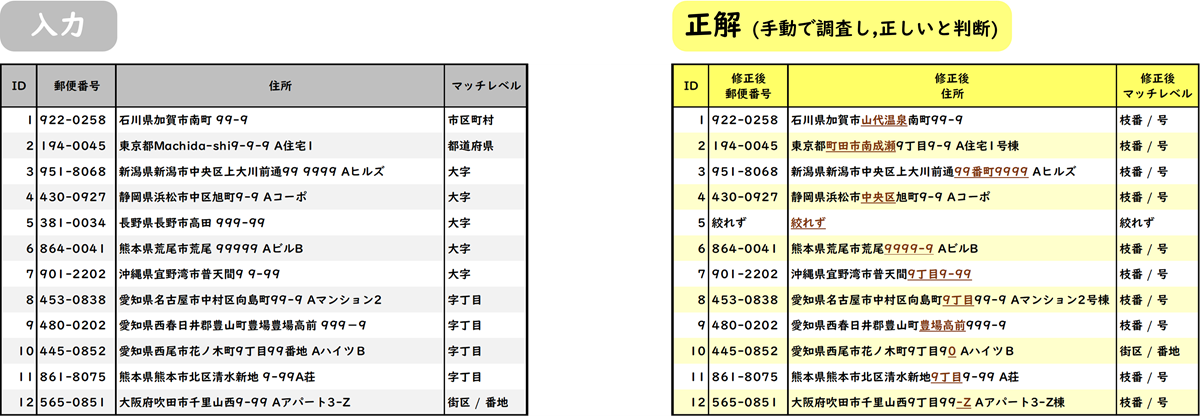
作成した入力データと生成AIの出力データ、手動で調べた正解(模範解答)
※ダミー化しております。
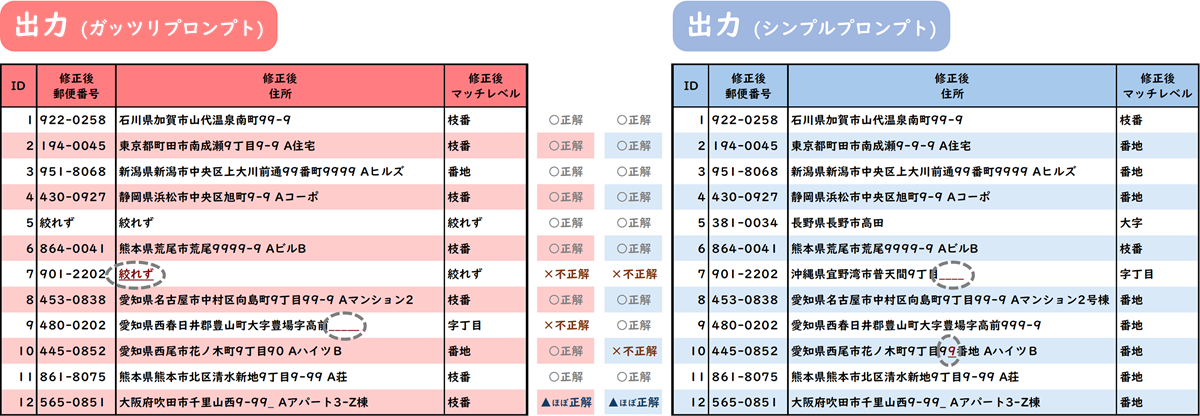
※精度の検証は住所のみで行っています。プロンプトの定義上、シンプルプロンプトは『絞れず』を出力できません。
※思考型のプロンプトにつきまして、YouTube等で情報収集した内容を
NotebookLMで要約・整理してみました(クリックで展開)
- 「思考のさせ方」を指示しない
- Thinkingモデルは既にどう考えるべきかを学習済みであるため、ユーザーが思考手順を指示すると、モデルの良さを引き出せない可能性があります。
- プロンプトはシンプルで直接的なものが推奨されています。
- 「目的」と「制約事項」を明確にする
- 目的:どういう目的でそのタスクを行ってほしいのか。
- 制約事項:ページ数や形式など、タスクを行う上でのルール。余計なことを書かずに、これらを明確に伝えるだけで十分機能するとされています。
- 「専門家としての役割(ペルソナ)」を設定しない
- 実験では、専門家として振る舞わせると、通常のプロンプトよりもスコアが低下するケースが確認されています。
- 理由としては、特定の役割を設定することで、モデルがその専門家が持っているはずの知識範囲に限定され、本来持っている他の有用な知識を使わなくなってしまうためではないかと考察されています。
- ただし、精度向上ではなく、カスタマーサービスなどで口調を制御したい場合には役割設定を行っても良いとしています。
- 複雑な構造化は不要
- 「最初の入力」ですべてを完結させる(マルチターンを避ける)
- 1回目の入力が最も精度が高いため、なるべく最初のプロンプトで完結させるべきです。
- 会話を続ける必要がある場合は、これまでの内容を要約させ、新しいチャットで改めて1回目の入力として指示を出す方法が推奨されています。
「思考型モデル プロンプト テクニック」で検索するとヒットします(2026年1月末時点)
実務で見えた「思考型モデル」の扱い方
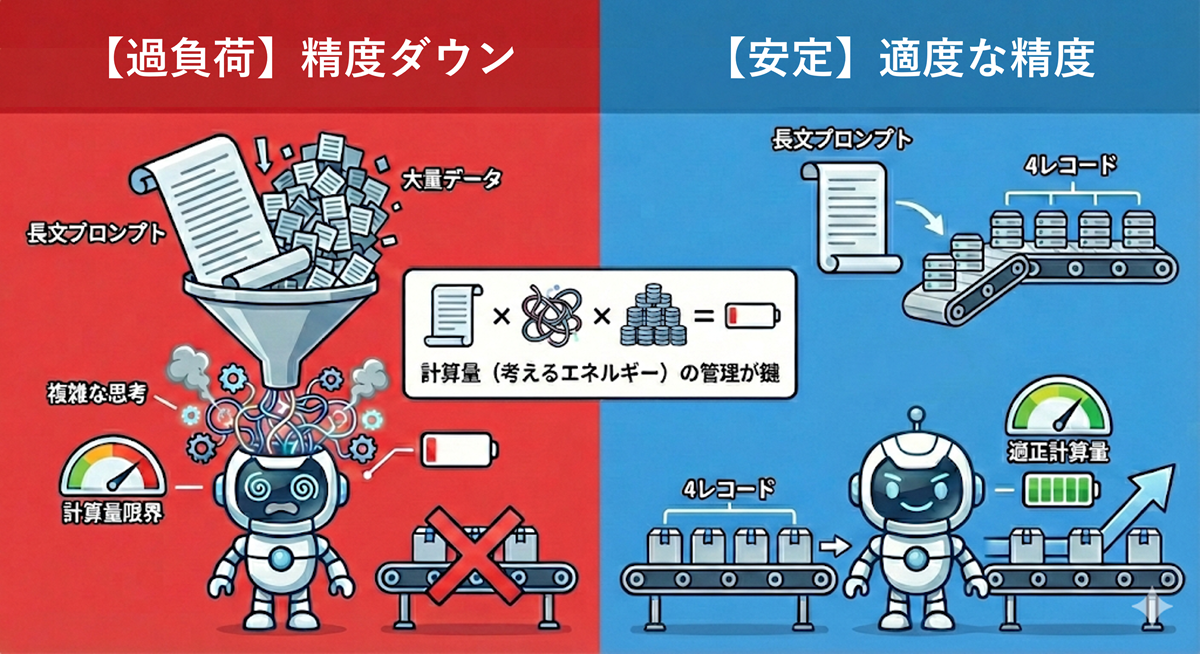
今回の「ガッツリプロンプト」は、まず私がたたき台を作成して検証しました。そのうえで誤った回答が出たときは、「プロンプトのどこが原因か」をChatGPTに問い、修正を繰り返しました。とにかく 住所の改善パターンの網羅を最優先に進めた 結果、文字数は10,000を超え、ChatGPTが全体を把握しづらいだろうと感じていました。
実際に、 一度に多くのデータを渡すと、要件を取りこぼしたり、思考の途中なのに回答をはじめたり して、精度が落ちる傾向がありました。私は当初、精度低下の最大要因は「10,000字という文字量の多さ」ではないかと仮説を立てました。そこでChatGPTに意見を求めたところ、返ってきた答えは 「半分正しく、半分間違い」 でした。要点は次の通りです。
本質は 情報量そのものより、要求した処理の負荷(複雑さ×件数 ≒ 計算量)にある 、ということ。長いプロンプトに加え、複雑な思考プロセスと処理件数が掛け算され、結果としてキャパシティを超えた可能性が高いようです。つまり、情報量の多さだけでなく、同時にやらせた作業量が増えすぎたことで品質が落ちた(または落ちたように見えた)というイメージです。
性能を引き出すためには、挙動を理解した上でプロンプトを設計することが大事だと考えさせられました。
今回はシンプルに「1回につき4レコードずつ」に分けて入力することで対処しました。
「書き方」から「目的」の時代へ
今回の結果に、最初は正直ガッカリしました。でも、ここには重要な教訓がありました。
-
細かい手順の押し付けは、状況によって逆効果になりうる:
手順を全部書くほど「負荷」が上がり、上限に近づくと省略や取りこぼしが出やすい。トップアスリートに動作を細かく指示しすぎるとパフォーマンスが落ちるのに似ている気がします。
-
まずは"目的と制約"を短く固定し、重い処理は分割するのが強い:
「正しい住所を出力して」「フォーマットに沿って」「根拠を示して」のように"目的と制約"の設定を明確にしつつ、レコード数や出力量を分割して負荷を下げると、結果が安定しやすい。
-
1週間の努力は無駄ではない:
プロンプトを作る過程で、私自身が「住所クレンジングの論理構造」を整理できました。そして何より生成AIが「どのような仕組みで回答をしているのか」を理解することが大事だと気付きました。
最後に
それにしても、AIの進化のスピードには驚かされっぱなしです。
プロンプトエンジニアリングは「どう書くか」という言い回しのテクニック以上に、「何を解決したいか(課題定義 / 目的)」と「制約を上手くかけ、どう成立させるか」を捉え、わかりやすく伝える必要があるようです。※数か月後には全く違うことを言っているかもしれません
住所クレンジングの精度を求めていたはずなのに、全然違う締めになってしまいました。
今回もお読みいただき、ありがとうございました。
参考:検証に使用したプロンプト
1. ガッツリプロンプト【見出しのみ】(クリックで展開)
【あなたの役割】
【ユーザーの背景】
【あなたのミッション】
【作業の流れ】
【処理の流れ】
<0. 入力仕様(ユーザーによる)>
<1. 出力仕様(必須)>
<2. 正規化ルール(必須・推測ではなく機械的処理)>
≪2-1. 表記統一≫
≪2-2. 注記・ノイズの除去(住所本体から除外)≫
≪2-3. 建物名の取り扱い≫
≪2-4. 京都の通り名の扱い≫
<3. 住所分解ルール(必須)>
<4. 「住所構造(構造1/2/3/4)」の判定ルール(必須)>
≪4-1. 混在時の扱い≫
<5. 「一意にヒット」の判定基準(必須)≫
≪5-1. POI(建物名)による一意ヒット(例外)≫
≪5-2. 単一サイト起点の「横展開検証」による一意化(準例外・必須条件付き)≫
〔5-2-1. 適用条件(すべて必須)〕
〔5-2-2. 採用ルール(採用できる場合)〕
〔5-2-3. 不採用(絞れず)となる条件〕
<6. 検索の優先順位(必須)>
<7. 郵便番号の扱い(厳守)>
<8. 「絞れず」の条件(必須)>
<9. 出力する「修正後住所」の原則(重要)>
≪9-1. 地図サイト正式表記による「中間地名(上位要素の追加)」補完≫
<10. IDごとの処理>
≪10-1. 初期化(必須)≫
≪10-2. 前提処理:正規化・分解(必須)≫
≪10-3. 前提処理:大字までで住所構造(構造1/2/3/4)を判定(必須)≫
≪10-4. 建物名がある場合:建物で一意化を最優先(必須)≫
〔10-4-1. 住所本体+建物名(地図サイトで確定)〕
〔10-4-2. Web検索は「候補取得のみ」→確定は地図サイト〕
≪10-5. 建物名が無い/建物名で確定できない場合:構造別処理≫
〔10-5-A. 構造1(大字(町名)+番地(+枝番) 型)〕
〔10-5-B. 構造2(大字(町名)+小字+番地(+枝番) 型)〕
〔10-5-C. 構造3(大字(町名)+丁目+住居番号/番地 型)〕
〔10-5-D. 構造4 または 判定不能〕
≪10-5-E. 単一サイト起点の横展開検証(5-2)(必須:救済手順)≫
〔10-5-E-1. 起点サイトで住所候補(表示住所)を取得〕
〔10-5-E-2. 住所候補で他サイトを再検索(横展開)〕
〔10-5-E-3. 採用判定(最終)〕
≪10-6. 採用・出力の共通ルール(必須)≫
≪10-7. 修正後マッチレベル「手動」の扱い【重要】≫
〔10-7-1. 「手動」判定の機械条件(必須)〕
【フューショット(Few-shot)】
<入力>
<出力>
2. シンプルプロンプト(クリックで展開)
指示そのものは実質1行。あとは出力形式の指定のみです。
ユーザーが入力する"ID,郵便番号,住所,マッチレベル"はジオコーダーによる作業結果で、住所に不備があるなどの理由によりマッチ粒度が高くありません。粘り強く調査を行い根拠のある正しい住所を以下のフォーマットにより出力してください。
# (csv)出力フォーマット
あなたは入力の各行(ID単位)について、必ず次の列を出力する。
- ID(入力のIDをそのまま出力)
- 郵便番号(入力の郵便番号をそのまま出力)
- 住所(入力の住所をそのまま出力)
- マッチレベル(入力のマッチレベルをそのまま出力)
- 修正後マッチレベル(都道府県 / 市区町村 / 大字 / 字丁目 / 街区 / 番地 / 枝番 / 絞れず のいずれか。修正後住所の粒度に一致させる。)
- 修正後郵便番号
- 修正後住所(正規化・補完後の最終住所。)
- 不備原因(入力住所によるマッチレベルが番地 / 枝番にならなかった理由)
- 改善内容
- 判断と改善の詳細
- 確認サイト
- 根拠となったURL(修正後住所の根拠となったURLを出力(複数可))
- 検索ログ(試したクエリを順番に列挙)





