

どうも!sodaエンジニアの國田です。
Stable Diffusionのオープンソース公開から早1ヶ月半が経過しようとしています。
最近では次々とハイクオリティなモデルもリリースされ、二次元キャラクター画像に特化したNovelAIなんて有料サービスも登場してきております。
生成AIがブログやSNS上でも賑わいを見せる一方で、なかなか思い通りの絵が描けない、なんて声もよく聞きます。
Stable Diffusionのようなテキストを使って画像を生成するモデルは、かなり自由度が高い手法と言われているのですが、実際問題として、最新アニメに登場するヒロインや、日本のボディビル大会の参加者、ご当地キャラの生成といったようなタスクはあまり得意ではありません。
これは、ひとえに生成モデルの学習にCLIPが使われていることに由来します。
CLIPはペアになる画像とテキストの組みを何億組も学習させたモデルで、画像とテキストがどれほど似ているか(=類似度)を出力するモデルになります。
類似度と言うと、単なる1つの数字と思われがちですが、実際には無数の数値の羅列(ベクトル)に画像とテキストをそれぞれ変換し、それらの個々の数値が互いに近い値を示しているのか、といったことを比較しています。
生成AIは、このCLIPを使い、ユーザーから受け取ったテキストに最も近い画像を描くというメカニズムなのですが、CLIPの中に含まれていない画像はそもそも出力することが難しいです。
先ほど言った最新アニメやご当地キャラなんていうものは、CLIPの中にない画像・テキストにあたりますので、当然うまく画像を生成することができないのです。
では、上記のような画像を生成させたい場合にどうすれば良いのでしょうか?
アニメのヒロインの画像とテキストで学習したCLIPを新しく用意するしかないのでしょうか?「△△というアニメの□□という名前のヒロインが〇〇している」といったテキストを全部作って学習させるなんて途方もない作業です。
なんとか、画像だけでその概念を生成モデルに伝える方法は無いのでしょうか?
実は、あるんです。そんな方法が。
Textual Inversion
「Textual Inversion」。和訳しますと、「言葉の埋め込み」ですね。
これを使うと、数枚の画像だけでAIに新しい概念を画像だけで教えこむファインチューニングができるようになります。
以前のブログで、Image Inversionと呼ばれる生成モデルを使って手持ちの画像をAIで再現させる方法を紹介しましたが、今回ご紹介するのはそのテキスト版です。
手法を簡単に解説します。
以下のようなTシャツの画像があったとします。
この時、このTシャツの画像を生成するためのテキストは分からないものとします。
生成AIには、この画像の特徴を押さえてもらい、この模様を再現できるよう学習してもらいます。
では、どのようにAIに特徴をとらえてもらえば良いのでしょうか?画像の特徴を示すテキストが分からない以上、かなり難しそうですよね?
とりあえず、テキストが無いと何も始められないので、この画像が持っている概念を仮に「X」という単語で表現するとしましょう。
先ほど、「CLIPではテキストを数値の羅列(ベクトル)に変換して、類似度を計算している」と言いました。つまり、この「X」を示す数値の羅列(ベクトル)が画像と似た値になるように調整してあげれば、いい感じに単語「X」が示す概念が画像と一致していきそうです。
① 仮のテキスト(例: An illustration of X)をCLIPで数値の羅列(ベクトル)に変換する。
② 柄物のTシャツの画像と①のテキストの類似度を算出する。
誤差逆伝播を行い、 数値を更新する(≒その類似度が大きくなってくれるベクトルへと書き換える)。
③ 類似度が⼗分に大きくなるまで②を繰り返す。これにより、数値化されたXは、画像と限りなく似たものに近づいていく。
④ 得られた埋込ベクトルを生成AIに入力し、新しい画像を⽣成させる。
この方法を図に示すと以下のようになります。(生成AI部分についてはこちらの記事を読んでからの方が理解しやすいかと思います。)
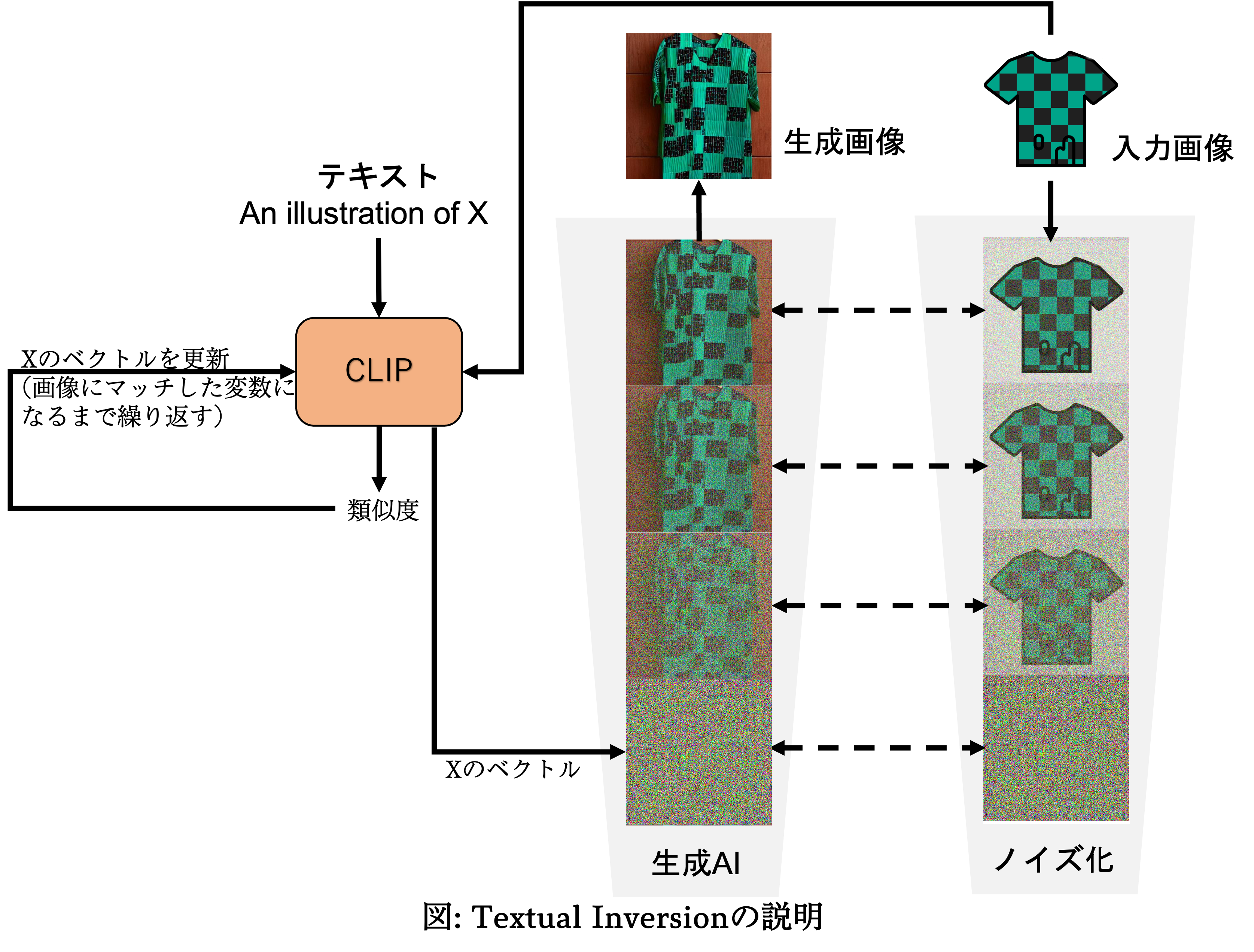
以上のプロセスにより「X」という単語は、「何かよく分からないけども、画像との類似度が非常に高い言葉」に変わります。具体的な名付けを行わないままに、数値表現として画像の示す概念を「X」という言葉へと置き換えてしまうのです。
ちなみに本手法は"An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion"(Rinon et al., 2022)[1]という論文で紹介されています。
タイトルを日本語に訳しますと「画像は言葉と同じ重みがある」。なんとも面白いタイトルだと思いませんか?
実際にやってみた
では、上記を踏まえ、実験してみましょう。
先ほど例で挙げた模様を生成させてみます。
ファインチューニングに使ったのは下記のような画像です。これらを合計20枚ほど用意しました。
以降、学習によって手に入れた表現を表す言葉を「X」とします。
まず、「A T-shirt in the style of X」(XのTシャツ)と入力してAIに画像を作らせてみます。



しっかりと表現が獲得できているようです。
もう少しやってみましょう。
「Corgie with X」(コーギーとX)とすると、



かなり曖昧なテキストで指示しましたが、それぞれ良い感じに反映させてくれていますね。
このように、様々な意味を彷彿させるテキストでも生成AIはあらゆる可能性を考慮して、なるべくすべての可能性を考慮した画像を生成していることが分かるかと思います。
では、続けて他の実験もしてみましょう。
今度は直接的に特定の人物やキャラクターを生成したい場合を考えてみます。
下記のような画像を合計6枚用意して、ファインチューニングします。(全て私の顔画像です。)



CLIPの学習データの中には私が存在していないため、本来であれば私の画像を生成することなどできない筈です。
ですが、Textual Inversionのおかげで以下のような画像を生成できるようになります。
「A photo of X」(Xの写真)



自分で言うのもなんですが、クオリティ高いですね!
わずか6枚の画像だけでここまで再現できるのが本手法の恐ろしいところ。今回は簡単な実験ですので、あまり追究はしませんが、本気でクオリティの向上を目指そうと思えば、画像の学習枚数を増やしたり、学習時間を増やすことで問題なくいけそうです。
さらに、これを利用することで、イラストの生成もできちゃいます!
「An anime illustration of X」(Xのアニメ風イラスト)と入力すると、



こんな感じで、自画像イラストも簡単に生成することができます!
勿論、与えるテキストをうまく考えることでここからさらにイラストのクオリティを上げていくことも可能ですよ!
以上、今回は生成AIのファインチューニングを可能にする「Textual Inversion」という技術について解説しました。生成AI自体は自由度が非常に高い手法ではありますので、上記のような画像だって「A man with a glasses and black hair」(黒髪でメガネをかけた男性)みたいな表現をうまく工夫していけば、生成することだって不可能ではないかも知れません。しかしながら、なかなかドンピシャになってくれない、そのような悩みを解決する手法としてTextual Inversionは非常に有効に働いてくれると思います。
このような技術があることで、生成AIは様々な課題に対応できるようになるでしょう。際限なく成長させることができますし、それにより目的ごとに特化した生成モデルも次々と誕生していくに違いありません。
最近の生成AIの発展はとにかくスピードが速く、日々新しい技術が登場しています。
「AIの民主化」などと言う言葉では追いつかないくらい加速度的にAI技術が取り入れられているのも事実です。
日常に完全にAIが溶け込むまでにもはやそう時間はかからないのではないでしょうか。
我々の日常が今後、どのように変化していくのか、本当に楽しみですね!
参考
[1] Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik and Daniel Cohen-Or, "An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion", 2022





