

どうも、sodaエンジニアの國田です。
最近、ChatGPTによる画像生成(4o Image Generation)が話題ですね。
「チャットを通じてユーザーの指示を正確に理解し、それを画像に落とし込める」という点は、インタラクティブかつマルチモーダルなモデルとして、一つの到達点と言えるでしょう。
ChatGPTの4o Image Generationは非常に高いコンテキスト(文脈)把握能力を持っていますが、その一方で気になるのが生成スピードです。画像1枚の生成におよそ1分程度かかってしまうため、
つい「何よりも ―― 速 さ が 足 り な い !!」と叫びたくなります。
私は、もともと、GANから画像生成AIを触ってきたこともあり、特に画像生成速度には、こだわりがあります。
しかしながら、最近の画像生成モデルの主流は、拡散モデル(Diffusion Model)と呼ばれる手法で、これがどうしても時間のかかる原因になっています。
今の時代、生成速度の速いモデルは絶滅してしまったのでしょうか?
結論から言えば、速いモデルはちゃんと存在しています。
その中でも今回はSDXL TurboおよびSDXL Lightningというモデルを紹介したいと思います。
SDXL TurboおよびLightningは、当ブログでも何度か取り上げているStable Diffusion系のモデルです。
(ちなみに、Turboは、Stable Diffusionの開発元である Stability AI社 が提供するモデル。一方、Lightningは TikTokの開発元であるByteDance社 によって提案されました。)
いずれも、拡散モデルの高品質さを維持しながら、生成速度を大幅に短縮することを目指しているのですが、まず、なぜ従来のStable Diffusionが時間がかかるのかを簡単におさらいしておきましょう。
Stable Diffusionの基本原理:なぜ時間がかかるのか?
Stable Diffusionでは、「ノイズのかかった画像(正確には圧縮された潜在ベクトル)」を、
U-Netと呼ばれるノイズ除去モデルに通し、少しずつノイズを取り除くことで画像を生成します(下図)。
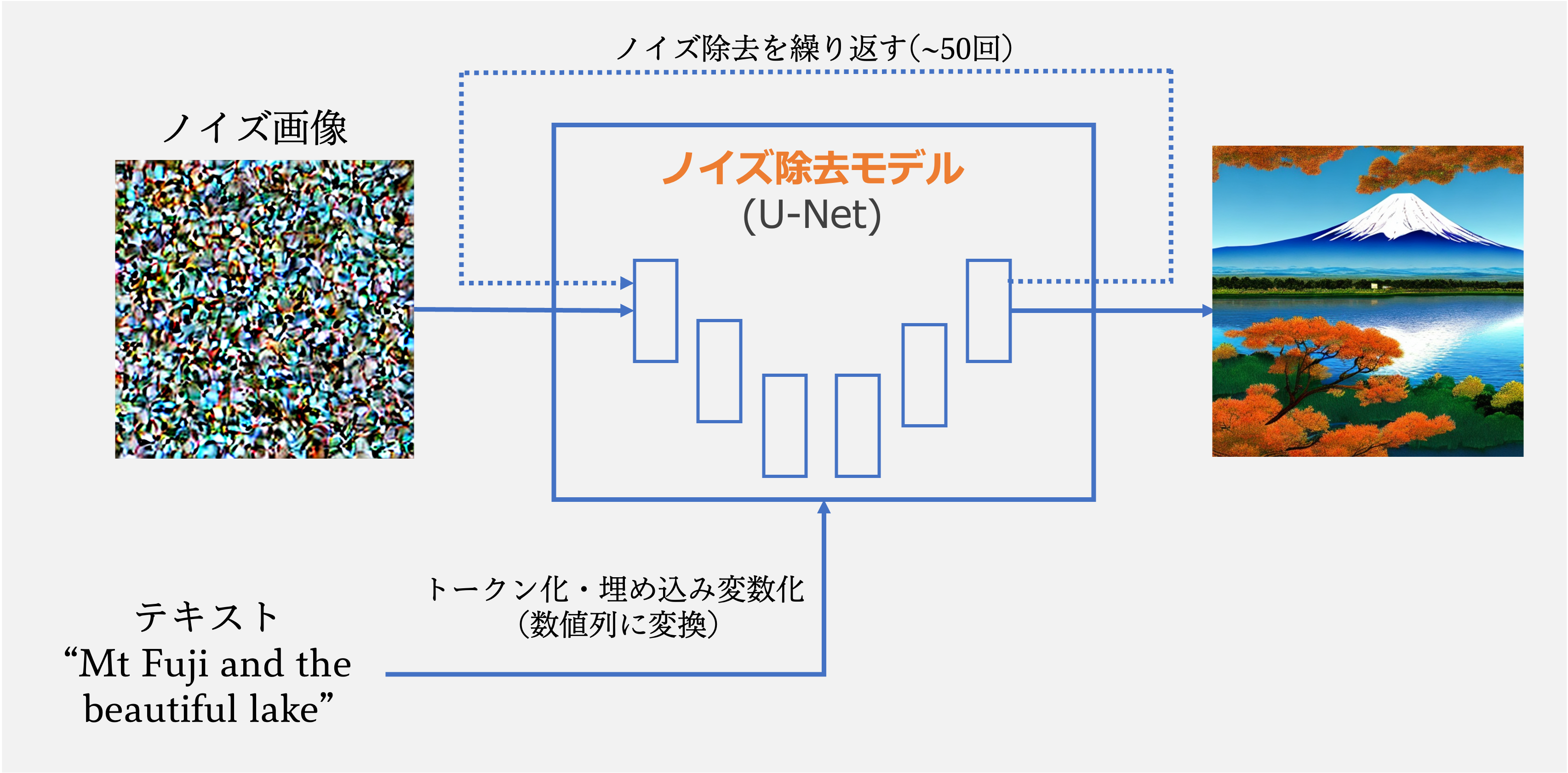
このノイズ除去は一回では終わりません。
以下のGIFのように、ノイズだらけの画像から少しずつノイズを除去していく必要があり、繰り返し繰り返しU-Netを通過させなくてはいけないのです。
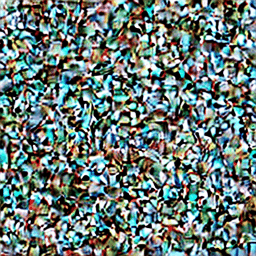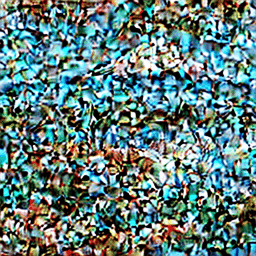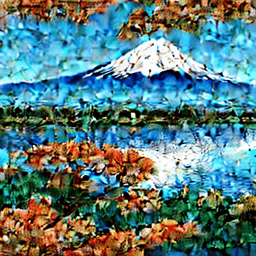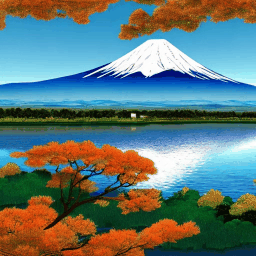
通常は50回前後、多いと100回以上このステップを繰り返すため、結果として、どうしても生成完了までに時間がかかります。
(Stable Diffusionの原理について、「もっと詳しく知りたい!」という方はこちらをご覧ください。)
で、やはり出てくるのは「このノイズ除去を1〜2回で済ませられないのか?」という疑問ですよね?
そこで登場するのが SDXL Turbo [1]です。
SDXL Turbo
SDXL Turboは、Diffusion Modelの生成過程にGANの手法を取り入れたAdversarial Diffusion Distillation (ADD)という手法を使っています。
Adversarial Diffusion Distillation (ADD)
「Adversarial Diffusion Distillation(敵対的拡散蒸留)」とは、高速かつ高品質な画像生成を実現するために、先ほど挙げたノイズ除去(Diffusion Model)と、蒸留(Distillation)、そして敵対的学習(Adversarial Learning)を組み合わせた新しい手法です。
まず、蒸留(Distillation)と敵対的学習(Adversarial Learning)について説明します。
1. 蒸留(Distillation)
先ほど述べたように、Stable Diffusionのノイズ除去のステップは何十回も繰り返す必要があり、生成には時間がかかります。この課題を解決するために、以下のような2つのモデルを考えます。
- 教師モデル(Teacher):大元のStable Diffusionモデル。時間をかけて、数十回のステップのノイズ除去を実施し、丁寧に画像を生成する高性能モデル。
- 生徒モデル(Student):より少ないステップ(例えば数回)で、教師と同等レベルの画像を生成できることを目指す、軽量・高速モデル。
蒸留では、生徒モデルが数回のノイズ除去ステップだけで「教師モデルの出力を真似できるように学習」します。
これにより、少ないステップでもそれなりに高品質な画像が作れるようになります。
しかしながら、この蒸留のプロセスで、きちんと教師モデルの出力に似た画像が生成できるかどうかは曖昧です。
と言うのは、教師と生徒のモデルがそれぞれ異なる画像を出力したとき、それらが「同じくらい良い画像だ」と判断するのは簡単ではないからです。
たとえば、以下のように「バーベルを持つボディビルダー」というプロンプトで生成した画像について考えてみましょう。この中で、どれが良い画像で、どれが悪い画像か、人間でも全く判断がつかないのではないでしょうか?

そこで登場するのが敵対的学習(Adversarial Learning)になります。
2. 敵対的学習(Adversarial Learning)
「生徒が出力した画像が教師と同じくらい良い画像か?」という評価の難しさを解決するために、GAN(敵対的生成ネットワーク)に使われている敵対的学習を取り入れます。
GANの仕組みを振り返ってみましょう。
GANでは以下の2つのネットワークが競い合います:
- 生成器(Generator):リアルな画像を作ろうとする。
- 識別器(Discriminator):それが本物か偽物かを見抜こうとする。
ADDではこのアイデアを流用し、識別器に「これは教師モデルの出力か?それとも生徒モデルか?」を判断させるという仕組みを使います。
つまり、生徒モデルは「識別器を騙して、教師モデルが生成した画像のように見える画像を出す」よう学習するのです。これによって、生徒モデルの出力が教師モデルの水準に近づけることができるのです。
SDXL Turboはわずか数秒で画像を生成することができます。まさに爆速・・!
SDXL Lightning
続けて、SDXL Lightning[2]です。
SDXL Lightningは、ADDを更に発展させたPADD(Progressive Adversarial Diffusion Distillation)という手法を用いています。
PADD(Progressive Adversarial Diffusion Distillation)
Progressiveは「段階的」という意味です。SDXL Turboの蒸留では、教師モデルが多数の拡散ステップ(例:数十〜百数十ステップ)を必要とするところを、いきなり数回(1〜4ステップなど)に削減するような学習を行っていました。
これは、
- 学習が不安定になりやすい
- モデルの品質が劣化しやすい
などといった問題を孕んでいます。
そこで SDXL Lightningでは、ステップ数を段階的に減らしていくというプロセスを採用しています。
具体的には:
- 最初は、教師モデル(例:128ステップ)の出力を、生徒モデル(32ステップ)が模倣するように学習させる。
- その学習済みの生徒モデル(32ステップ)を、新たな教師モデルとして再利用する。
- 次にその教師モデルを基に、より少ないステップ(8回、4回、2回、1回...)へと徐々に落としていく。
このように、段階を踏んで徐々にステップ数を減らすことで、安定した学習と高品質な出力を両立しているのです。
潜在空間上での敵対的学習
SDXL Lightning では、学習効率をさらに高めるために、敵対的学習をどの空間で実行するか に工夫が施されています。
先ほどのSDXL Turboなどの手法では、既製の画像エンコーダを識別器として利用していました。そのため、画像が「教師画像のものか、生徒画像のものか?」を判断するためには、一旦画像の生成完了のプロセスまで完遂させねばならず、
計算量・メモリ消費・学習時間が大きくなってしまう問題がありました。
そこで SDXL Lightning では、
- わざわざ高解像度の画像に戻さず、潜在空間のまま(デコード前の状態)で敵対的学習を行う
- 判別器として ノイズ除去モデルのエンコーダ部分を流用し、「教師の出力か?生徒の出力か?」を潜在空間で効率的に判断
この設計により、高解像度画像を生成・保存するコストを抑えつつ、学習の質を保つことに成功しています。
まさに「『光速』の異名を持ち、画像生成を自在に操るモデル」と言えるでしょう。
生成画像・生成速度の比較
さて、以上を踏まえて実際に生成速度を比較してみたいと思います。
Google Colab上で、T4 GPUを使い、通常のStable Diffusion XLと、最先端のSDXL Lightningの生成速度を比較してみましょう。
Stable Diffusion XL
SDXL Lightning
いかがでしょうか?
圧倒的に生成速度が違うのがお分かりになるかと思います。
せっかくですので、生成される画像のクオリティも比較してみましょう。
SDXLで生成した画像およびLightningで生成した画像を並べてみます。

蒸留モデルになったことによるクオリティの劣化も見られませんね!
まとめ
いかがでしたか?
最近は、画像生成AIのコンテキスト理解能力の向上に関する研究が進む一方で、今回紹介した Turbo や Lightning のように、生成速度の高速化を重視したモデルの開発も活発に行われています。
特に text-to-image タスクにおいては、モデルが入力テキストを正確に解釈する能力はもちろん重要ですが、それと同じくらい「わずか数秒で画像生成ができること」が、実際の運用シーンでは不可欠です。
私自身は、個人的にスピード感を重視する立場です。
生成に1分かかるモデルで1枚の画像ができる間に、高速なモデルであれば数十枚の画像を生成できる。その中に「これだ!」と思える1枚があれば、それで十分ではないか?
そのように考えています。
今回、久しぶりにStable Diffusion関連のお話をしましたが、過去に『Software Design』という雑誌でも、2023年6月号~2024年1月号まで、画像生成AIの原理について解説記事を連載していました。もしご興味があれば、ぜひそちらもご覧いただけると嬉しいです。
また、それ以外にも画像生成AI、特にStable Diffusionに関するセミナーで定期的に講師を務めております。もし機会がありましたら、ぜひご参加ください。
ではまた!
参考
[1] Axel Sauer, Dominik Lorenz, Andreas Blattmann and Robin Rombach, "Adversarial Diffusion Distillation", 2023, https://static1.squarespace.com/static/6213c340453c3f502425776e/t/65663480a92fba51d0e1023f/1733935148453/adversarial_diffusion_distillation.pdf
[2] Shanchuan Lin, Anran Wang and Xiao Yang, "SDXL-Lightning: Progressive Adversarial Diffusion Distillation", 2024, https://arxiv.org/pdf/2402.13929





