

どうも!sodaエンジニアの國田です。
Stable Diffusionがオープンソース化されたことで、テキストを入力するだけで画像を生成する手法は生成AIの一般的な手法となりつつあります。
当ブログでも様々な生成モデルを取り上げていますが、その全てがテキストのみで生成するモデルというわけではありませんでした。
例えばStyleGANなどは初めに適当なパラメータを入力して画像を生成させる手法をとっており、「金髪の眼鏡をかけた女性の画像が欲しいなぁ」とか「筋肉質な精悍な男性の写真が欲しいなぁ」と思っても、テキスト入力を受け付けているわけではないため、逐一数値で探索させたりと結構な手間がかかります。
こういった問題に対するアプローチとして、手持ちの画像をテキストによって編集したり、テキストを使って新しいGANのモデルを作る手法などを紹介してきましたが、いずれも「既存のモデルによる画像生成→テキストで作り替え・アレンジ」というような段階を踏む手法でした。
やはり直接「金髪の眼鏡をかけた女性」と入力して、その画像を生成してもらうという方法が楽な気がします。
既存のモデルをうまく使って、テキストで任意の画像を取り出す方法って無いのでしょうか?
実はあるのです、そんな夢のような方法が。
clip2latent
というわけで、今回はStyleGANへテキストを渡し、そのテキストにマッチした画像を生成させる方法について解説します。
まずは、GANの生成器のにおける画像の生成方法を振り返ってみましょう。
GANの生成器は元々、学習した画像全てに共通する概念的なものを学習しているのでした。そして、その概念のことを「潜在空間」と呼んでいます。(例えば、顔画像を生成するGANの生成器では「目が2つあって、鼻が中央にあって、口があって・・」といった概念を獲得しています。)
GANの生成器では、その潜在空間内の数値を取り出して、画像を生成します。(ここで使っている潜在空間内の数値を潜在変数と言います。)以下の図をご覧ください。
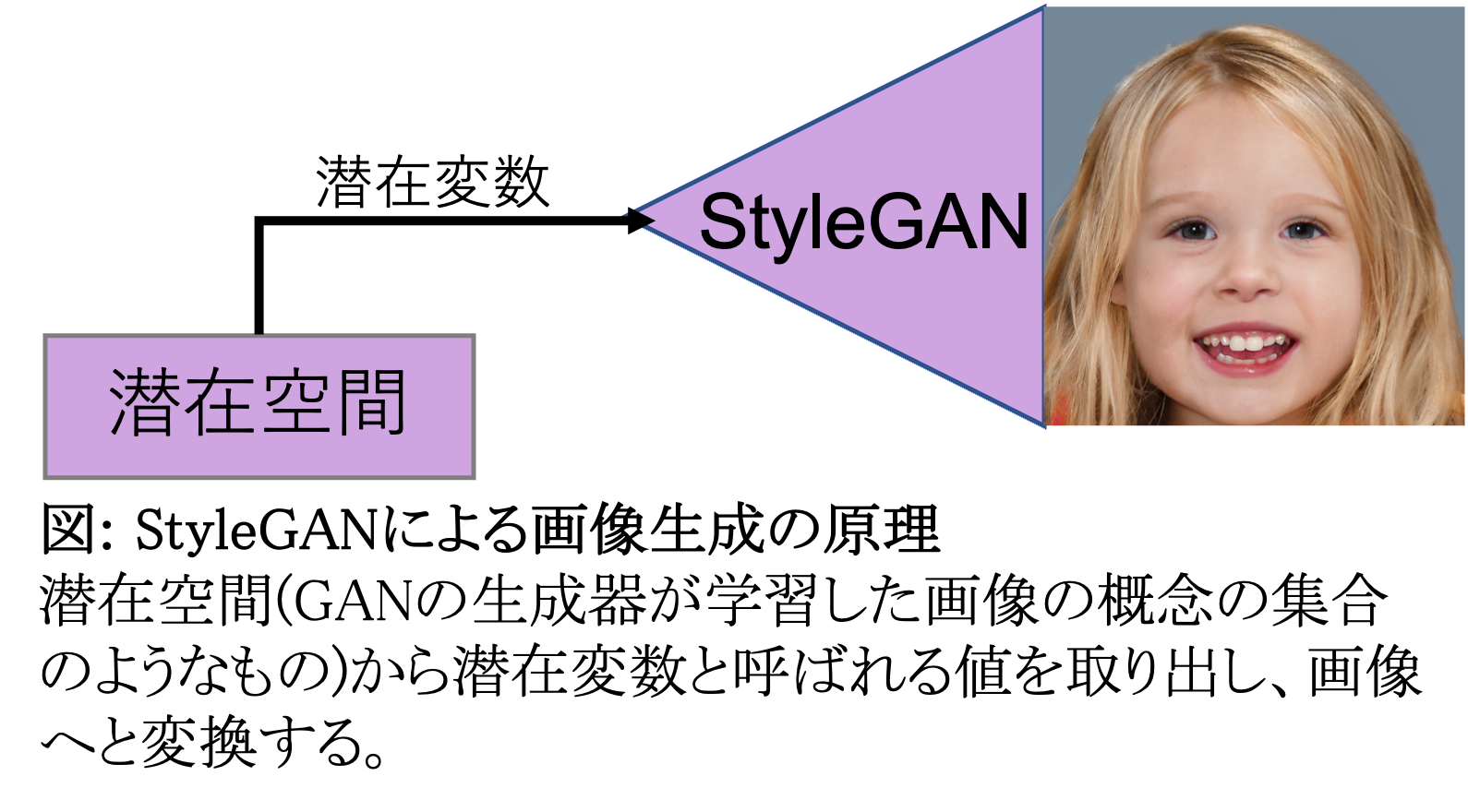
ここで使用する数値が変われば、生成される画像も違うものへと変わります。
問題は、この数値が何を表しているかがブラックボックスである点です。例えば、上の画像の例では金髪の女の子の画像が生成されていますが、これを男の子に変えたり、黒髪に変えたりするにはどんな変数にすれば良いかが人の目には見えません。
これをサポートするために利用するのが、CLIPになります。
CLIPは、「テキストの表す内容と画像がどれだけ似ているか?」を算出する際に使われるモデルで、画像とテキストをお互いに比較可能な形へと変換することができます。
今回は少し突っ込んで、CLIPがどうやってテキストと画像を比較しているのかを、説明させていただきます。以下の図をご覧ください。
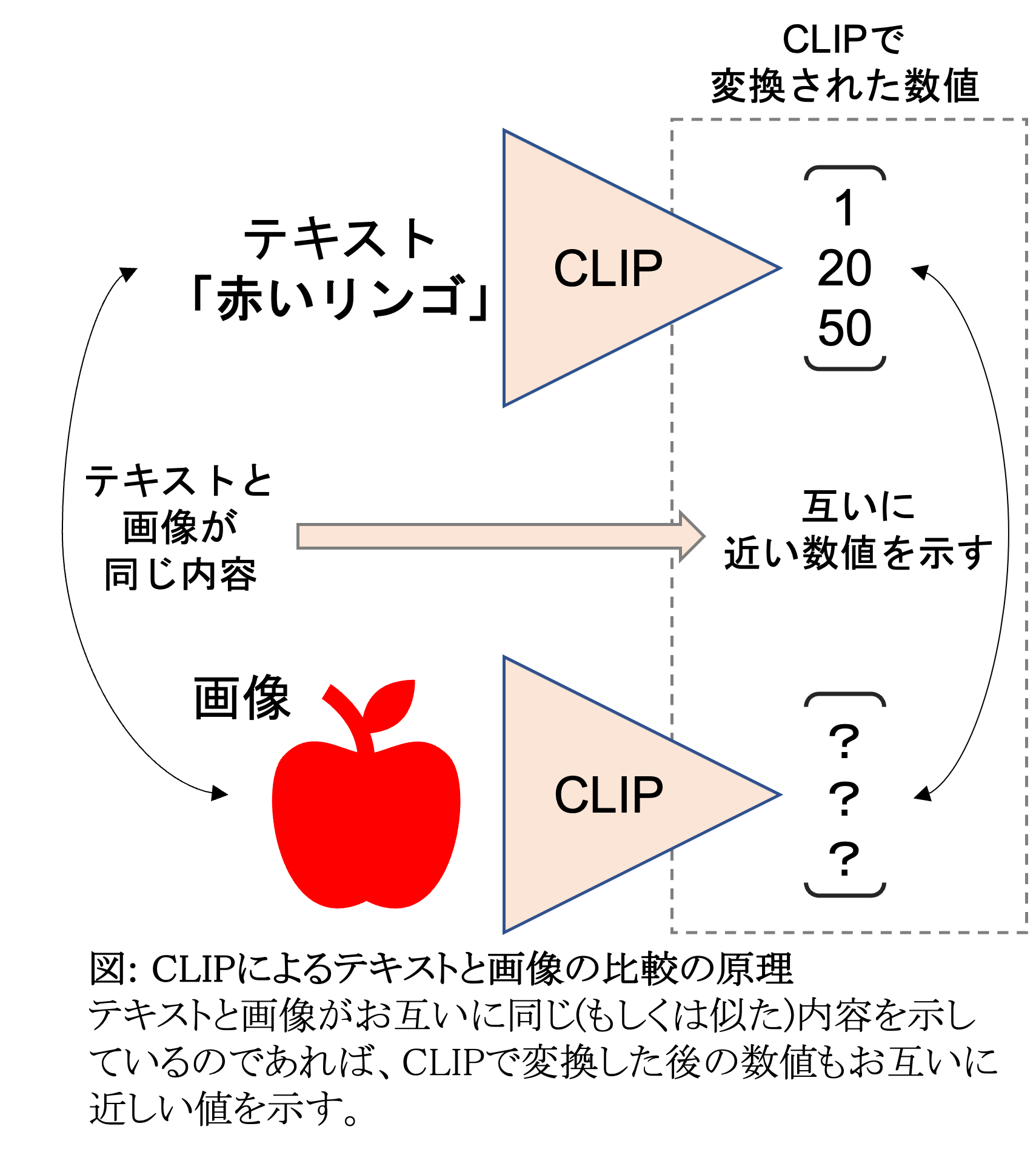
「赤いリンゴ」というテキストをCLIPで処理した際に、[1, 20, 50]という数値の羅列が得られたとします。(あくまで例です。本当の数値表現はもっと沢山の数字が並んでいて複雑です。)
では、そのテキストに似た画像、赤いリンゴそのものの画像をCLIPで処理するとどうなるでしょうか?[1.1, 21, 49]とか[0.9, 18, 51]といった値になる筈です。
この時、テキストから得られた値と、画像から得られた値を比較するとどうでしょうか?
1番目の数値:1に対し1.1とか0.9
2番目の数値:20に対し21とか18
3番目の数値:50に対し49とか51
同じ位置にある数値の値が似たような値になっていますよね?これが「画像とテキストが似ている」ということです。CLIPは同じ概念を示すものが互いに近い値になるよう、処理の段階であらかじめ調整してくれているのですね。
つまり、最近の生成モデルの「テキストで指示する」とは、「CLIPで変換された数値を生成AIに渡している」ということです。
では、ここでGANの生成した画像をCLIPで変換してみましょう。
得られるのは数値の羅列ですが、この数値の羅列自体が「生成画像を表すテキスト」と同義であることはお分かりかと思います。
この性質を利用することで以下のようなモデルを作ることができます。
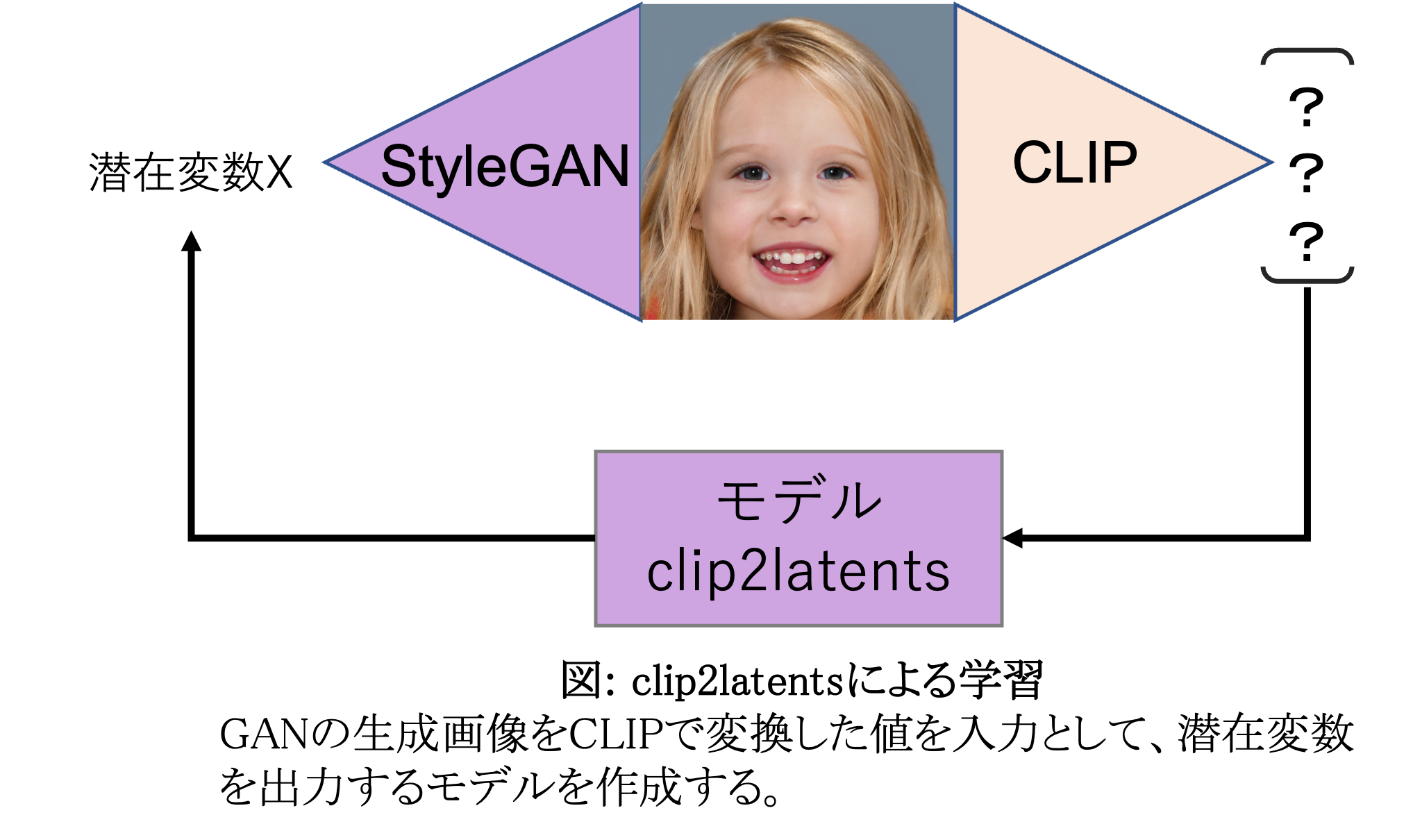
モデル作成の流れとしましては、
①適当な潜在変数を使い、画像を生成
②生成した画像をCLIPで数値化
③②で得られた値を入力とし、①の値を予測するモデル(clip2latent)をトレーニング
となります。
このモデルはCLIPで変換された値から潜在変数を予測するというかなり単純なモデルです。
先ほど述べた通り「CLIPで変換されたテキストと画像は内容が一緒であれば近い値」になりますので、このモデルにテキストを入力すれば、それに対応する潜在変数を予測、その潜在変数をStyleGANに渡すことでテキストに沿った画像が生成できることなります。
入力にはCLIPで変換した値を使っているのに、
学習時には「画像から変換した数値」を、
推論時には「テキストから変換した数値」を使っているのが面白いですよね!
更に詳しい説明を知りたい方は、原論文[1]の方も参照いただけるとありがたいです。
さぁ、やってみよう
では、実験してみましょう。
まずは顔画像のモデルを使い、具体的にテキストで画像の詳細を入力することで本当にその画像が得られるのかテストしてみます。
まずは"A photograph of a young woman with ear rings(イヤリングを付けた若い女性の写真)"としてみましょう。
 |
 |
2枚ほど画像を生成させてみました。きちんと「若い女性」「イヤリング」といった要素を反映した画像が生成されました。では、もう少し条件を付けてやってみましょう。
"A photograph of a young blonde woman with ear rings(イヤリングを付けた若い金髪の女性の写真)"
 |
 |
良いですね。「Blonde」もきちんと拾ってくれているようです。
では、"A photograph of a young blonde woman with eyeglasses and ear rings(イヤリングを付けたメガネの若い金髪の女性の写真)"
 |
 |
かなり精密にできるようです。
他の条件でもやってみましょう。
"middle aged man with beard and a happy expression by the sea"(海の側で顎髭を蓄えた中年男性が微笑んでいる)
 |
 |
"Chinese man with large sunglasses and a nagative expression by the forest"(森のそばでサングラスをかけた中国人がネガティブな表情をしている)
 |
 |
サングラスとネガティブ系の表情という難しい条件を出しました。
「大丈夫かな?」と少し心配でしたが、口の開き方がやや悲しげに見える気もしますね。
驚くべきことにこれらの画像は0.5秒ほどで生成されます。Diffusion Modelで生成する画像が20~30秒程度かかることから考えると、GAN(CNN)で画像を生成するのも物凄くメリットがあるようにも思えますね。
ただ、Diffusion Modelと比較して、多様な画像の生成が苦手なのは事実です。特に、今回の場合ですと、GANの生成器の潜在空間内に存在する画像しか生成できません。人の顔画像を生成するモデルの場合ですと、例えば、"Hatsune Miku"と入力すると以下のような画像が生成されます。
 |
 |
色的な雰囲気の近いものをGANの生成器の潜在空間上から探したことは分かりますが、そこに近い画像となると生成が難しいようです。Diffusion Modelとは異なり、学習で獲得した概念とあまりにも離れている画像は呼び出すことはできません。
違うモデルでも試してみましょう。風景のモデルが公開されておりますので、同じようにテキストから生成させてみます。
"Tropical beach in Asia"(アジアの熱帯ビーチ)
 |
 |
"Sunsetting over the mountain"(山の向こうの夕暮れ)
 |
 |
"Windows XP wallpaper"(Windows XPの壁紙)
 |
 |
それっぽい画像が生成されますね!
以上、既存のGANの生成画像をテキストから呼び出す手法について紹介しました。
この方法の秀逸な点は、外部データや微調整なしで、既存の生成モデルを使用してtext-drivenなサンプリングを可能にしている点です。本来、同じテキストから画像を生成するモデルを作るとなると、画像に対してテキストのラベル付けを行なって大量のデータを流し込みながら学習をさせなくてはなりません。それがGANの生成器とCLIPだけでできているのは、個人的には圧巻の一言です。
おまけ
今回のおまけ。CLIP使っているということは、勿論、有名人の画像を生成できます。今回はGANの潜在空間の中から似ている人を探してみました。
|
アインシュタイン
|
ベートーヴェン
|


|
ニュートン
|
マリー・アントワネット
|


|
ナポレオン
|
クレオパトラ
|


ニュートンはなぜか女性っぽく仕上がっていますね。
実際の写真のない人でもGANで生成させることによって「歴史上の偉人がもし現代に生まれていたら?」みたいな妄想もできそうです。
ではまた!
参考
[1] Justin N. M. Pinkney and Chuan Li., "clip2latent: Text driven sampling of a pre-trained StyleGAN using denoising diffusion and CLIP" 2022





