

BERTは2018年末頃にgoogleが発表した、自然言語処理における深層学習を用いた画期的なモデルです。(BERTはBidirectional Encoder Representations from Transformersの略)
何故注目されているのか?
自然言語処理の分野には、色々なタスクがあります。例えば、文章分類、質疑応答、文章要約、翻訳・・・各々のタスクを解くために、それぞれに設計されたモデルが存在していましたが、BERTはその一つのモデルを用いて、たくさんの自然言語処理のタスクで同時にSoTA(State of The Art: 簡単に言うとその時点でのハイスコア)を叩き出しました。BERT以前の自然言語処理のモデルは、タスクにより精度のバラツキが有るが、BERTは全てのタスク於いて精度が高いことがわかります。あらゆる自然言語処理タスクはこのBERTを土台にして取り組めるため、自然言語処理の汎用モデルとして使えるという気運が高まっています。
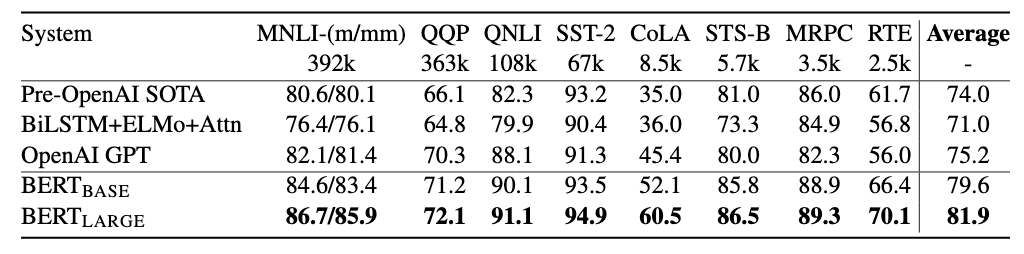
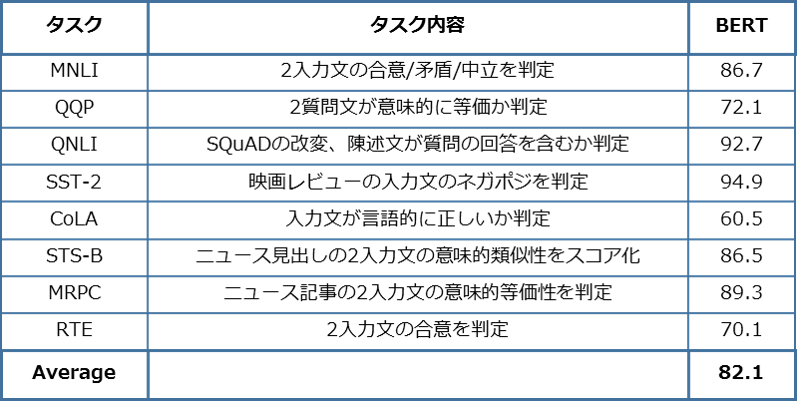
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, Devlin, J. et al. (2018) より
BERTの仕組み
BERTの仕組みの基本は、TransformerのEncoder部分を複数重ねたものです。Transformer自体は、BERTから約1年前に登場した、NLPにおいてとても注目されているモデルになります。
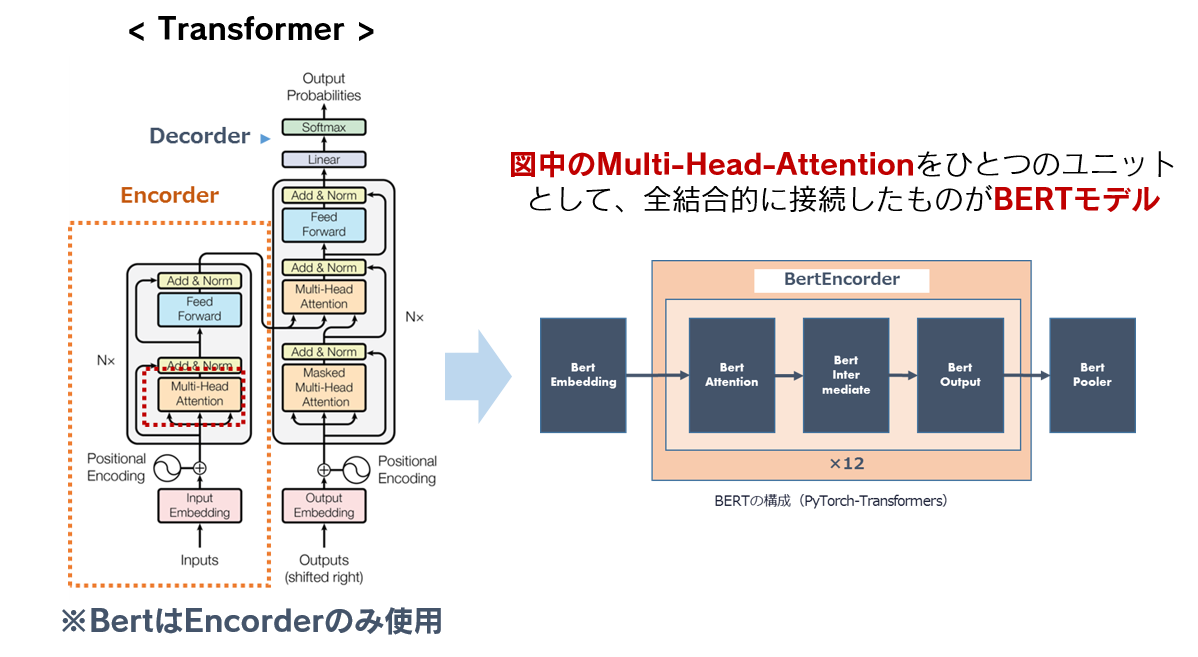
Attention Is All You Need, Ashish, V. et al. (2017) より
BERTが自然言語処理のブレークスルーとなったポイントは?
BERTがブレークスルーとなったポイントをまとめると以下の3点です。
- TransformerのAttentionを活用。Self Attention=文法の構造や単語同士の関係性、照応関係などの情報を獲得するために使用。
- 事前学習としてMLM(=Masked Language Modeling)とNSP(Next Sentence Prediction)を学習させることで飛躍的に精度向上。
- 様々なNLPタスクにファインチューニング可能なモデル。
BERT以前の言語モデルは前にある単語から後ろに続く単語を予測したり、文章の中で近い距離にある単語同士の関係を把握したりするだけでしたが、BERTは文章中の遠い距離にある単語同士の関係を把握したり、文脈を基に文章の各所にあるべき単語を予測したりできるようになり、自然言語処理精度が飛躍的に向上しました。
BERTや自然言語処理の活用にご興味のある方、詳しい説明が必要な方はこちらからお気軽にお問合せください。また、BERTを活用した事例をこちらでご紹介しています。





