
こんにちは。sodaデータプランナーの吉田です。
先日、ChatGPT関連の書籍を読んでいると、「統計情報を地図上に可視化する」という事例が紹介されていました。通常、地理情報を扱うには、GISソフトを使うのが一般的です。私自身、GISソフトを10年ほど利用しています。ChatGPTの分析機能で、どこまで地理情報を利用できるのか? 個人的には大変興味深い問題です。
そこで今回は、名古屋市の人口推移の分析を通じて、ChatGPTにできることを検証しました。まずは、GIS(地理情報システム)について簡単に説明し、その後、具体的な分析プロセスを紹介します。
そもそもGISとは?
GIS(地理情報システム)は、地理的なデータを分析し、それを地図上に表示するためのシステムです。エリアマーケティングの分野では、地理的な位置情報を持つデータを可視化することで、市場環境の理解や店舗立地の選定などに役立ちます。
例えば、新規店舗の出店場所を選定する際には、周辺の人口密度や年齢分布、競合店の位置、交通の便など、商圏内の情報を総合的に判断する必要があります。また、既存店舗のマーケティング戦略を考える際には、地図上にプロットした顧客情報と統計情報を掛け合わせることで、エリアセグメントごとの広告配信や、ターゲットに合わせたプロモーションを展開することもできます。さらに、集客状況を時系列で比較することで、プロモーションの効果を検証したり、新しくオープンした競合店など、外部環境の変化による影響を把握したりすることもできます。
地名のリストや、顧客の住所だけを見ていても、地理的な関連や変化は見えにくいですが、GISはこれらの要素を視覚的に示し、直感的な理解を助けてくれるのです。
地理情報分析のためのツール
冒頭で述べた通り、地理情報の分析にはGISソフトがよく使われています。有名どころだと、Esri社のArcGIS、Precisely (旧Pitney Bowes)社のMapInfoなどがあります。
GISソフトは直感的な操作が可能で、地図の作成やデータの可視化が簡単に行えますが、ライセンス費用が高いことや、特定の操作が複雑であるというデメリットもあります。これらの有償ソフトは会社で契約したものを使うことが主流ですが、業務に合わせて機能をカスタマイズしているような場合、保守が切れるたびに大掛かりなシステム移行や、社内教育のやり直しが発生して、大きな業務負担になることもあります。私もこれまで3つのソフトに触れてきましたが、その度に機能の名称やUIが変わってしまい、苦労した経験があります。
そこでGISソフトを使わず、Pythonを用いる手法もあります。Pythonには多くのライブラリがあり、例えば、geopandasを使うことで、簡単に地理データを操作し、可視化することができます。また、shapelyを使えば、地理データの操作がさらに柔軟に行えます。
Pythonの強力な点は、これらのライブラリを組み合わせて、独自の分析ツールを作成できることです。Pythonを用いた地理情報分析は無料で柔軟にカスタマイズ可能ですが、プログラミングの知識が必要です。
ChatGPTは、Advanced Data Analysisという、Pythonを呼び出して実行する機能を持っています。こちらがプロンプトで指示をすれば、ChatGPTがPythonコードを実行します。さらに自然言語のやり取りによって、次の処理を進めていけるので、非常に強い味方になります。
ちなみに、GISソフトにはQGISという、無料で利用可能なオープンソースのソフトウェアがあります。QGISにはPythonコンソールから操作を行う機能が付いているので、ChatGPTにコードを作成してもらい、QGISで実行するという方法を取ることもできます。これを使うとかなりやれることが増えそうですが、今回はあくまでもChatGPTだけで作業を完結できる分析に絞って検証しています。
ChatGPTの利用環境について
今回の検証には有料のChatGPT Teamプランを利用しています。また、つい先日新しいGPT-4oモデルが発表されるなど、ChatGPTのバージョンアップのスピードは非常に速いです。さらに、Pythonやライブラリのバージョンもアップデートを繰り返しており、ライブラリ間の互換性の問題が発生して、分析が進まないことも多いです。
今回は、地理情報分析に用いるPythonライブラリとしては鉄板ともいえるgeopandasでエラーが頻発してしまったため、社内のエンジニアの方に相談して、下記の指示を追加しています。
- 読み込みはpyshpを使用してください。
- 可視化には、osgeo(GDAL), pyproj, shapely, geopyを使用し、geopandasは使用せずに地図を描画してください。
あるセッションで一度この指示を与えると、メモリ機能に内容が保存され、新しいセッションでも条件を引き継いでくれたので、非常に便利でした。
具体的な分析プロセス
さあ、ここからは実際の分析内容を見ていきましょう。今回は、愛知県のデータを使って分析を進めていきます。愛知県の地理情報に、2020年以降の将来推計人口を属性データとして付与し、その推移を地図上に可視化することを試みます。
契約内容やデータの提供方法にもよりますが、有償のGISソフトは、地形や行政区域、国勢調査などの基本的な統計データについては、あらかじめ組み込まれていることが多いです。しかもこれらのデータは、ユーザーが使いやすいように整えられています。一方、PythonやQGISなど無料で地理情報分析をしたいときは、まず目的に合ったオープンデータを入手し、整形する必要があります。
地理情報データの取得
まず、地図上に可視化するためのベースとなる、行政区のポリゴン(図形)データを取得します。愛知県の行政区域データは国土数値情報ダウンロードサイトから入手できます。フォルダの中身を見てみると、GML、GeoJSON、Shapefileの3つの形式のファイルがまとめて入っていました。今回はShapefile(.shp、.dbf、.shx、.prj)のみを別フォルダに入れてzipファイルにし、アップロードしました。
Shapefileは地理情報を保存するための一般的なフォーマットで、地理情報システムにおいて広く使用されています。Shapefileは、以下のような複数のファイルで構成されています。
- .shp:幾何学的なデータを格納するファイル。
- .shx:幾何学的なデータのインデックスを格納するファイル。
- .dbf:属性データを格納するファイル。
- .prj:空間参照情報を格納するファイル。
特に上3つの拡張子は、Shapefileを扱うために必須のファイルになります。これらのデータを適切に管理することで、地理的な分析を正確に行うことができます。
属性データの準備
次に、行政区ポリゴンに付属させる属性データを準備します。1つのポリゴンデータは、1レコードの属性情報に対応します。例えば、名古屋市千種区のポリゴンには市区町村コード: 23101、行政区名: 千種区 といった属性情報が付属しています。ウェブで公開されている様々な統計情報には、地理空間情報を含まないものも多くありますが、例えば市区町村コードをキーとして、Excelのフィールドを行政区ポリゴンに結合するという処理ができるのです。これによって、様々な情報を地図上に可視化することができます。
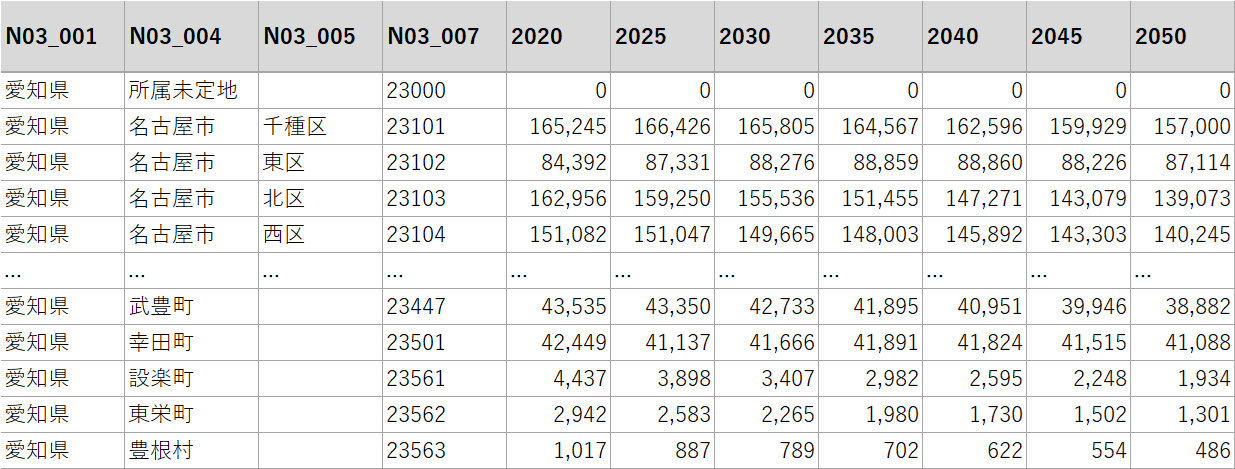
今回は、日本の将来推計人口データを属性情報として追加してみました。国立社会保障・人口問題研究所から、「都道府県・市区町村別の男女・年齢(5歳)階級別将来推計人口」というExcelデータをダウンロードします。このデータセットは、各市区町村の5年ごとの人口推計を提供しており、細かな年齢階級別に分かれています。
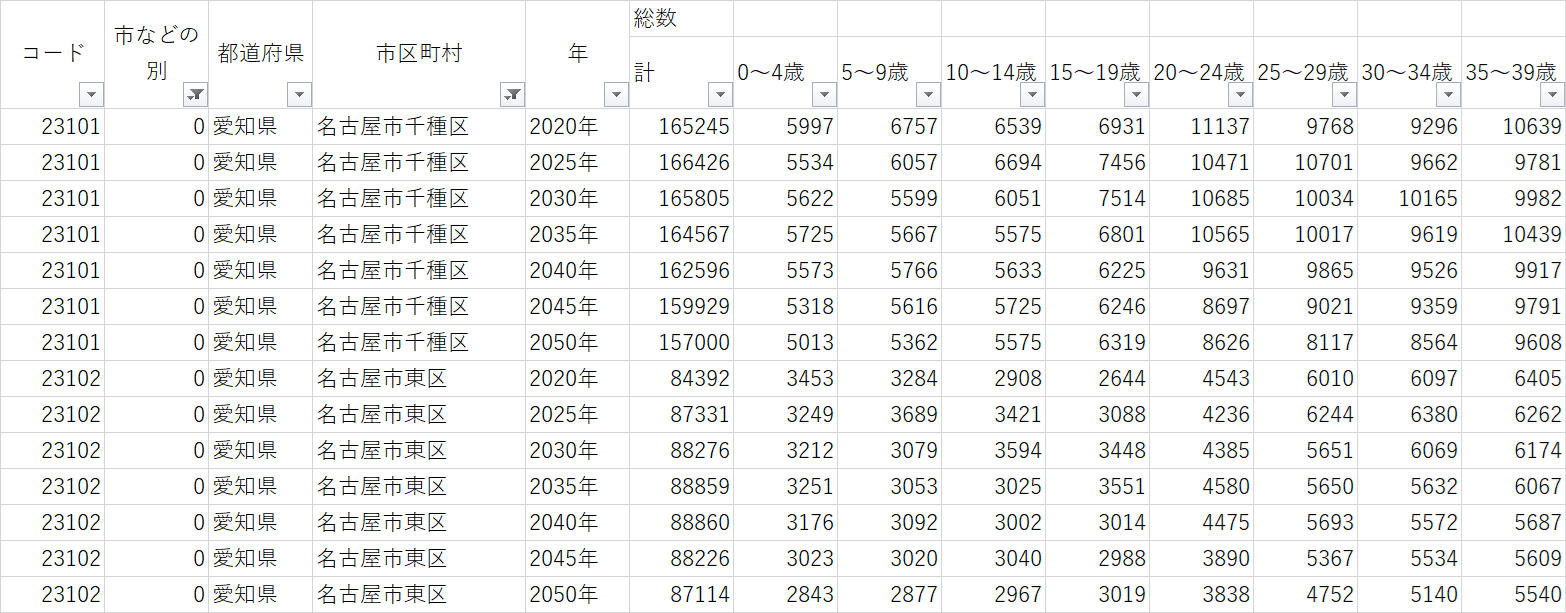
データの中身を見てみると、市区町村コードは行、5歳階級の区分は列という形で、推計人口の数値が並んでいます。さらに市区町村コードは2020年から2050年まで、5年ごとのデータを持っています。つまり同一の市区町村コードが、7行ずつ存在します。
今回は総数の推移を見たいと思います。GISソフトで同様の処理をする場合、まずこのExcelデータを整形し、行政区のレコード1行に対し、各年の人口総数が列として並んでいる状態にしてから、GISソフト上で結合を行います。しかし、このデータをExcel上で並び替えようとすると、かなり処理が面倒です。このデータ処理をプロンプトの指示だけでChatGPTにやってもらえたら、かなり楽が出来そうです。
属性データの結合と確認
アップロードするファイルは軽い方がいいので、一旦CSV形式で保存し直してから、ChatGPTに指示を出します。まず2020年の人口総数について、市区町村コードをキーとして属性データに追加するようお願いしました。
日本の将来推計人口データです。コードの列を文字列に変換し、N03_007カラムをキーとして、地図データの属性情報に2020年の総数を追加してください。
(「N03_007」はShapefileの市区町村コードに該当するカラム名です。)
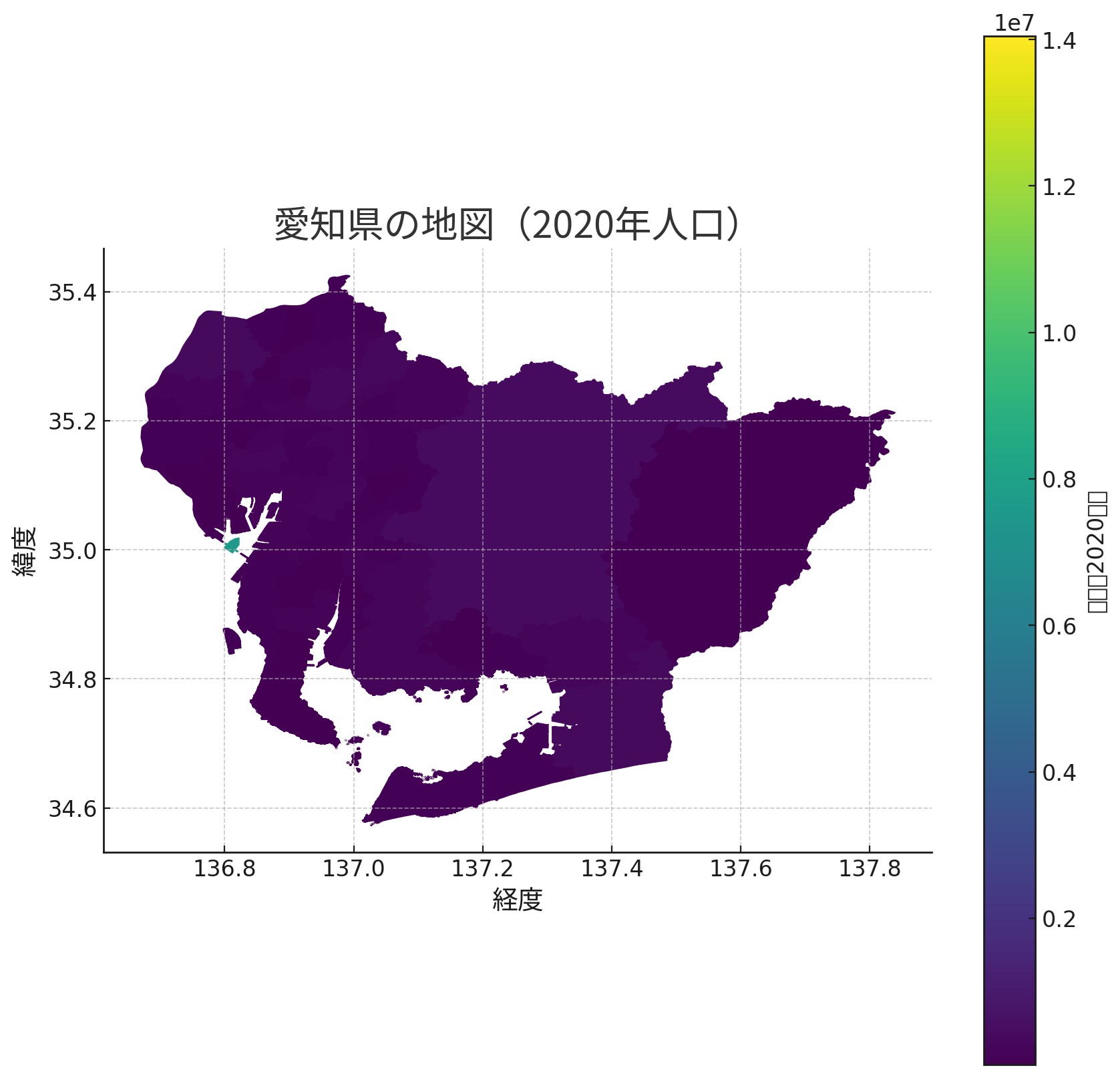
すると、属性データの結合結果を以下のように可視化してくれました。
所属未定地の処理
さて、この結果を見て、違和感を覚えませんか? 全体的に色の変化が見られません。さらによく見ると、一ヶ所だけ明らかに色が明るくなっている地域があります。愛知県にお住まいの方や、地図にお詳しい方は気づくかもしれませんが、そもそも愛知県にこんな行政区はないんですよね。利用したポリゴンデータに問題があるか、属性結合の処理が不適切だったのか、あるはずのない行政区に大きな数値が結合されてしまい、全体のレンジ幅もそれに引っ張られてしまっているようです。そこで、ChatGPTに聞いてみると、次のように原因を特定してくれました。
一番色が濃くなっている行政界は「所属未定地」(市区町村コード:23000)で、2020年の人口は7542415人です。これはおそらくデータの集計方法や分類に関する問題で、正確な市区町村名が特定されていない地域です。
実際には、海部郡飛島村に所属する地域ですが、人口が0のため、国土数値情報では所属未定地の扱いになっているようです。一方、CSVファイルには愛知県全体の集計行が存在したため、偶然市区町村コードが一致して、あり得ない数値が結合されてしまったということです。
また、ポリゴンデータのレコード数を確認してみると、1,035件もあることがわかりました。愛知県の市区町村コードは全部で69件なので、これは元データを確認した方がよさそうです。ここはやはりインタラクティブな処理をしたいので、QGISで中身を見てみると、一つの行政区でも沿岸部などが複数のポリゴンに分かれている場合があると分かりました。市区町村コードは同じなので、属性結合についてはこのままでも問題ないのですが、レコード数が多いと処理に時間がかかると思ったので、ここで同一の市区町村コードのポリゴンについては、図形を結合して1レコードにまとめる処理を行いました。なお、この処理もChatGPTにお願いすると、正しく結合してくれました。
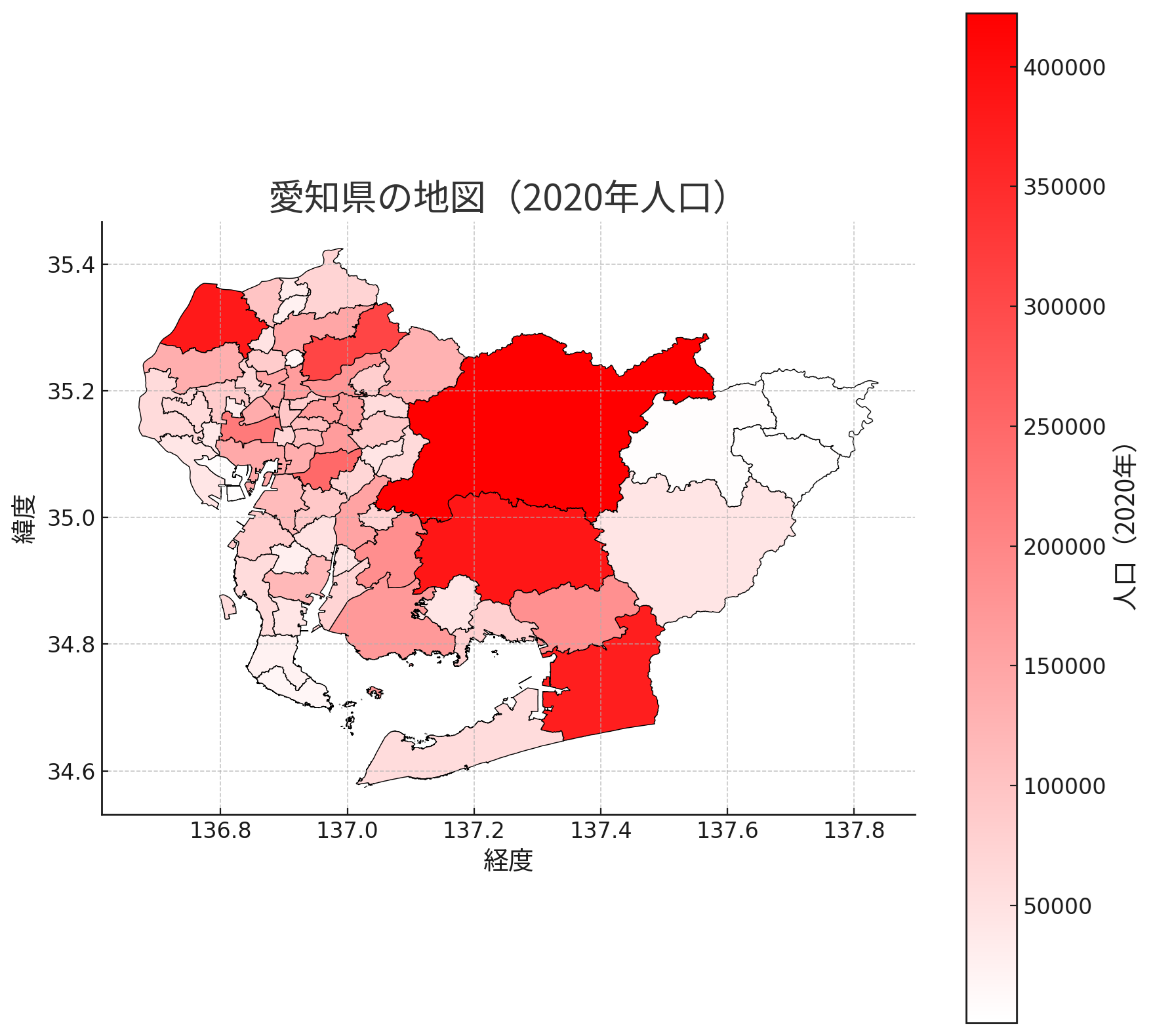
必要な処理ができたので、所属未定地を除いて再度可視化を行いました。さらに、理想の見た目になるように、以下の指示を追加しました。
- 愛知県の中で色が分かれるように、レンジの幅を調整してください。
- グラデーションを赤 - 白に変更してください。このとき、人口が多いほど赤色が濃くなるようにします。
- ポリゴンのラインを黒で表示してください。凡例の文字化けを修正してください。
すると、以下のように理想通りの地図が出力されました。
年ごとの人口データの結合
続いて、2025年から2050年の人口データも同様に結合しました。今回は結果を確認しながら進めることで、データの正確性を保つことができました。
2020年と同様に、2025年、2030年、2035年、2040年、2045年、2050年の人口を属性情報に追加してください。このとき、所属未定地の数値は0になるようにします。
結果は以下のように正しく処理されました。
2050年までの人口推移のアニメーション化
さて、ChatGPTは動画の作成もできるので、2020年から2050年までの人口推移をアニメーションで確認してみましょう。理想は愛知県全域で作成したかったのですが、データ量が多いと処理に時間がかかってしまい、応答がタイムアウトする現象が頻発しました。そこで残念ながら、ここからは対象エリアを名古屋市に絞って、続きの処理をお願いしました。このように、ChatGPTには処理の限界があるため、どこまで任せることができるのか、検証を重ねながら勘を養っていく必要がありますね。

さて、人口推移のアニメーションが出来上がりました。何度か指示は出し直しましたが、2020年から2050年の人口を、同一の基準で比較することができています。GISソフトでレンジ幅を決める際は、データの幅やバラつきを確認して、試行錯誤を繰り返すので、結構手間がかかるのですが、ChatGPTは勝手によさそうなレンジ幅を設定してくれるので、それを基準として調整の指示を与えればよいのが楽だなと感じました。
しかし、この結果だけ見ても、あまり具体的な考察は浮かんできません。土地勘があれば、住宅地は周辺部に散らばっているんだなとか、比較的若い世帯が多い緑区は2030年以降も人口増加の余地があるな、という程度のことはわかるのですが。そもそも行政区の大きさが違うので、実数による比較は限界があります。そこで、ChatGPTに人口増減率を計算してもらい、その推移をアニメーションにすることを試みました。
人口増減率の計算とアニメーション化
2020年に対する2025年から2050年の人口増減率の列を追加してください。処理が完了したら、属性情報を表形式で表示してください。
このように指示を出したところ、具体的な計算式は提示しなかったにもかかわらず、次のように正しい処理を行ってくれました。ゼロ除算の処理も問題なくできています。
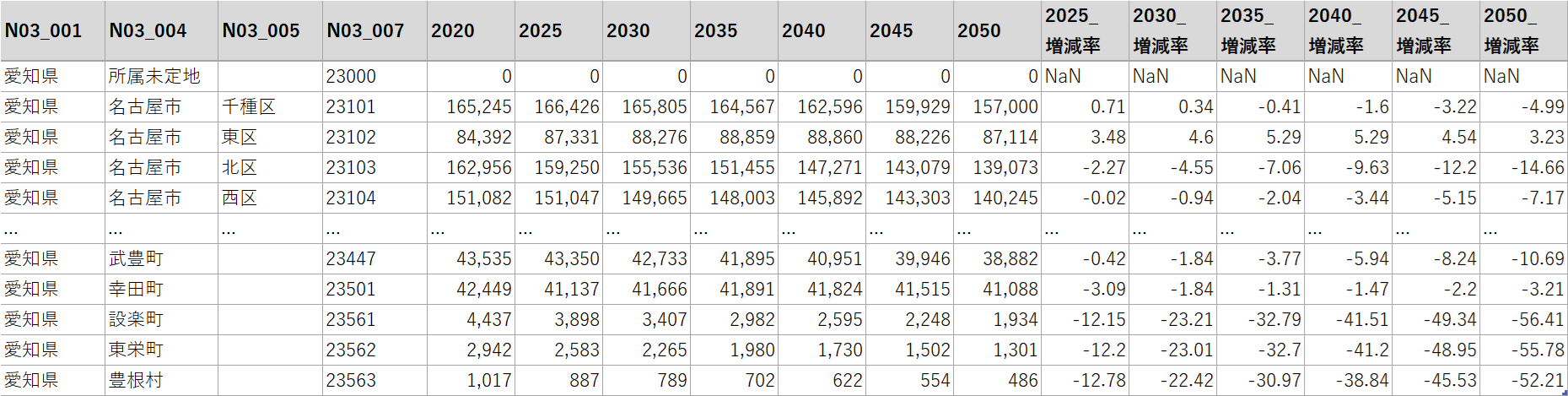
さらに、人口増減率の推移をアニメーションで可視化しました。レンジ幅については何回か指示を繰り返し、時系列の変化がよりとらえやすくなるように調整しました。最終的には-20%から20%までを5%刻みで区切り、0%を中心に白から青(減少)、白から赤(増加)へと色が変化するグラデーションで表示しました。これにより、どの地域で人口が増加し、どの地域で減少しているかを視覚的に把握することができるようになりました。

分析レポートの作成
せっかくなので、この結果について考察レポートも作成してもらいましょう。
この結果をもとに、名古屋市の人口推移と人口増減率推移について、増加率の大きいトップ3の地区と、減少率の大きいトップ3の地区について理由を考察し、解説レポートを作成してください。
具体的な数値を入れてください。増減率のランキングを再度確認し、正確な情報をレポートしてください。
1回目の指示ではめちゃくちゃな順位を出してきたので、具体的な数値を入れるよう指示すると結果が改善しました。出力結果は以下の通りです。
人口増加率の大きいトップ3の地区
人口減少率の大きいトップ3の地区
どうでしょう、なかなかにそれっぽいレポートを作成してくれました。とはいえ、ChatGPTにはハルシネーションの問題がありますので、より詳細な分析を行い、情報の正確性を判断する必要がありそうです。
まとめ
今回は、ChatGPTを用いて名古屋市の将来推計人口データを地図上に可視化する方法をご紹介しました。ChatGPTには処理の限界もありますが、部分的な作業には非常に有用です。例えば、次のような使い方が考えられます。
- 属性データの整形と結合を一気にやってもらう
- 属性データのフィールド追加と演算を一気にやってもらう
- データ範囲に合わせた適切なレンジ幅を決定してもらう
- 分析結果について考察レポートを作成してもらう
また、今回の分析で、所属未定地の処理を行った流れは、ChatGPTならではのものだなと感じました。従来であれば、最初にデータ内容を確認して整形してから進めるので、あまりこのようなプロセスは取りませんが、このようにプロンプトの会話を通じてデータの不備を特定し、修正が進められるのは非常に有用なのではないかと思います。(土地勘がない場合はスルーしてしまう可能性もあるので、違和感に気づくことができるかがポイントですが......。)
次回は、地価や土地利用に関するデータセットを用いて、さらに詳細な分析を行います。ChatGPTの考察内容は果たして正しいのか、検証していきたいと思います。お楽しみに!
エリアスコアリングは、sodaが提供するエリアマーケティングのためのプロダクトです。これは、既存の実績データと統計データをAIモデルで学習し、未知のエリアのポテンシャルをスコアリングするソリューションです。これにより、新たなエリアにおける顧客数や売上の予測が可能となり、効果的なエリアマーケティング戦略の策定を支援します。ご興味のある方は、エリアスコアリングの紹介ページをご覧ください。





